


SQLITE_ORM
用于编写数据密集型应用程序的C++
C++是一种大型语言,具有非常富有表现力和丰富的语法。也许它最显着的特征是它能够控制抽象级别,使应用程序编程能够根据问题域的概念来完成。此功能的扩展是能够根据“普通”C++代码定义域特定语言(DSL),如SQL。这使得C++成为编写数据密集型应用程序的一种非常引人注目的语言。
DSL 具有以下属性:
- 它是一种语言,它定义了:[CPPTMP,216]
- 字母表(一组符号)
- 定义明确的规则,说明如何使用字母表来构建格式良好的组合
- 所有格式良好的组合的明确定义的子集,这些组合被赋予了特定的含义
- 它是特定于域的,而不是通用的
- 示例包括正则表达式、UML、摩尔斯电码
- 通过这种限制,我们获得了更高层次的抽象和表现力,因为
- 专门的字母表和符号允许与我们的心智模型相匹配的模式匹配
- 允许以接近问题域抽象的术语编写代码是所有DSL背后的特征属性和动机
- 我们使用语言的符号来写下问题本身的陈述,语言的语义负责生成解决方案
- 最成功的DSL通常是声明式语言,为我们提供符号来描述什么而不是如何描述 * 如何被视为什么的结果
- 从某种意义上说,DSL是对面向对象编程的增强,其中开发是根据问题域概念模型完成的。
- 我们只是朝着丰富的符号支持迈出了额外的一步
本文档指的是一个名为SQLITE_ORM的SQL DSL,它为用C++编写SQL提供了直接支持。这确实是一项有价值的功能,并且允许清晰简洁地创建数据密集型应用程序。这个库不仅仅是一个SQL DSL,而是一种对象关系工具(ORM1),因为它提供了将C++中的数据结构与sqlite3中的关系表相关联的方法。
人们可以通过结合命令式C++编译时元编程和SQL增强来真正提高C++抽象级别。这种协同作用确实具有吸引力和强大性。
工作等级
SQLITE_ORM允许我们以两种根本不同的风格与持久对象进行交互:
- 按列(纯 SQL)
- 按对象(映射到结构的 SQL)
正是这种在对象级别处理持久性的支持解释了库名称的 ORM 后缀。基本上,数据库中的每个规范化表都可以在应用程序中以 1 对 1 关系表示为结构或类。这使我们能够在高度抽象上工作。我们将这些实例称为“持久原子”,以表明它们的规范化和牢不可破的性质。
另一方面,我们可以通过允许我们定义用于列的读取或写入查询来访问 SQL 的所有功能和表达式,就像您在关系客户端中工作一样,但是由于该库是域特定语言 (DSL)2 ,它允许我们使用C++代码编写 SQL。本文档专用于库的每个用户,可以认为是介于 SQL 和 SQLITE_ORM 之间的字典。
对象查询处理与对象类型关联的持久表实例的集合。该列查询访问持久表,在列级别处理相应对象类型。
将类型映射到表 – 使类型持久化
为了使用持久类型,我们需要将它们映射到表和列,并调用 make_storage(...),就像在这个例子中对 User 类型所做的那样
struct User {
int id = 0;
std::string name;
};
auto storage = make_storage(
{dbFileName},
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name)));
storage.sync_schema(); // synchronizes memory schema (called storage) with database schema
- 默认情况下,这将创建不可为空的列。要使一列可为空,例如名称,我们必须声明名称具有以下类型之一:
- 标准::可选
- 标准::unique_ptr>
- 标准::shared_ptr>
要记住的另一点是,字段可以具有任何可绑定的类型,其中包括所有基本C++数据类型,std::string 和 std::vector。可以使用其他类型,但您必须提供一些代码才能使它们可绑定(例如 std::chrono::sys_days)。例如,可以非常容易地绑定枚举。
简单查询
简单计算:
// Select 10/5;
auto rows = storage.select(10/5);
This statement produces std::vector<int>.
// Select 10/5, 2*4;
auto rows = storage.select(columns(10/5, 2*4));
This statement produces std::vector<std::tuple<int, int>>
常规选择语法:
SELECT DISTINCT column_list
FROM table_list
JOIN table ON join_condition
WHERE row_filter
ORDER BY column
LIMIT count OFFSET offset
GROUP BY column
HAVING group_filter;
一个表选择:
// SELECT name, id FROM User;
auto rows = storage.select(columns(&User::name, &User::id));
auto rows = storage.select(columns(&User::name, &User::id), from<User>());
这些语句是等价的,它们产生一个 std::vector>3 。省略 from 子句时,有一种算法可以检测语句中存在的所有类型,并将所有这些类型添加到 from 子句中。当只涉及一种类型时,这会立即起作用,但有时我们需要向其他表添加连接,在这种情况下,最好使用显式 from<>()。
// SELECT * FROM User;
auto rows = storage.select(asterisk<User>());// get all columns from User
Produces std::vector<std::tuple<std::string,int>>
auto objects = storage.get_all<User>(); // get all persistent instances of the User type
Produces std::vector<User>
处理大型结果集时
我们不必将整个结果集加载到内存中!我们可以迭代集合!
for(auto& employee: storage.iterate<Employee>()) {
cout << storage.dump(employee) << endl;
}
for(auto& hero: storage.iterate<MarvelHero>(where(length(&MarvelHero::name) < 6))) {
cout << "hero = " << storage.dump(hero) << endl;
}
对行进行排序
排序 Order by
一般语法:
// SELECT select_list FROM table ORDER BY column_1 ASC, column_2 DESC;
简单排序语法:
// SELECT "User"."first_name", "User"."last_name" FROM 'User' ORDER BY "User"."last_name" COLLATE NOCASE DESC
假设列的定义不可为空;否则,如果我们使用 std::Optional 来创建名称字段,它将是 std::vector,int>
auto rows = storage.select(columns(&User::first_name, &User::last_name), order_by(&User::last_name).desc().collate_nocase());
// SELECT "User"."id", "User"."first_name", "User"."last_name" FROM 'User' ORDER BY "User"."last_name" DESC
auto objects = storage.get_all<User>(order_by(&User::last_name).desc());
复合排序语法:
auto rows = storage.select(columns(&User::name, &User::age), multi_order_by(
order_by(&User::name).asc(),
order_by(&User::age).desc()));
auto objects = storage.get_all<User>(multi_order_by(
order_by(&User::name).asc(),
order_by(&User::age).desc()));
动态排序
Sometimes the exact arguments that determine ordering is not known until at runtime, which is why we have this alternative:
auto orderBy = dynamic_order_by(storage);
orderBy.push_back(order_by(&User::firstName).asc());
orderBy.push_back(order_by(&User::id).desc());
auto rows = storage.get_all<User>(orderBy);
函数排序
// SELECT ename, job from EMP order by substring(job, len(job)-1,2)
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_job),
order_by(substr(&Employee::m_job, length(&Employee::m_job) - 1, 2)));
排序时处理空值
// SELECT "Emp"."ename", "Emp"."salary", "Emp"."comm" FROM 'Emp' ORDER BY CASE WHEN "Emp"."comm" IS NULL THEN 0 ELSE
// 1 END DESC
auto rows = storage.select(
columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(case_<int>()
.when(is_null(&Employee::m_commission), then(0))
.else_(1)
.end()).desc());
这当然可以像下面这样简化,但使用 case_ 更强大(例如,当您有超过 2 个值时):
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(is_null(&Employee::m_commission)).asc());
对数据依赖键进行排序
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(case_<double>()
.when(is_equal(&Employee::m_job, "SalesMan"), then(&Employee::m_commission))
.else_(&Employee::m_salary)
.end()).desc());
筛选数据
选择非重复 Select distinct
SELECT DISTINCT select_list FROM table;
// SELECT DISTINT(name) FROM EMP5
auto names = storage.select(distinct(&Employee::name));
result is of type std::vector<std::optional<std::string>>
auto names = storage.select(distinct(columns(&Employee::name)));
result is of type std::vector<std::tuple<std::optional<std::string>>>
条件语句 Where Clause
SELECT column_list FROM table WHERE search_condition;
搜索条件可以由这些子句及其组合和/或组成:
- WHERE column_1 = 100;
- WHERE column_2 IN (1,2,3);
- WHERE column_3 LIKE 'An%';
- WHERE column_4 BETWEEN 10 AND 20;
- WHERE expression1 Op expression2
- Op 可以是任何比较运算符:
= (== in C++)!=, <> (!= in C++)<<=>=
// SELECT COMPANY.ID, COMPANY.NAME, COMPANY.AGE, DEPARTMENT.DEPT
// FROM COMPANY, DEPARTMENT
// WHERE COMPANY.ID = DEPARTMENT.EMP_ID;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(is_equal(&Employee::id, &Department::empId)));
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age,&Department::dept),
where(c(&Employee::id) == &Department::empId));
composite where clause: clause1 [and|or] clause2 … and can also be && , or can also be ||.
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId) and c(&Employee::age) < 20);
auto objects = storage.get_all<User>(where(lesser_or_equal(&User::id, 2)
and (like(&User::name, "T%") or glob(&User::name, "*S")))
where 子句也可以在 UPDATE 和 DELETE 语句中使用。
限制 Limit
通过查询(可选)限制返回的行数(限制),以指示要跳过的行数(偏移量)。
// SELECT column_list FROM table LIMIT row_count;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(4));
auto objects = storage.get_all<Employee>(limit(4));
// SELECT column_list FROM table LIMIT row_count OFFSET offset;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(4, offset(3)));
auto objects = storage.get_all<Employee>(limit(4, offset(3)));
// SELECT column_list FROM table LIMIT offset, row_count;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(3, 4));
auto objects = storage.get_all<Employee>(limit(3, 4));
通过以下方式将限制与顺序结合使用:
// get the 2 employees with the second and third higher salary
auto rows = storage.select(columns(&Employee::name, &Employee::salary), order_by(&Employee::salary).desc(),
limit(2, offset(1)));
auto objects = storage.get_all<Employee>(order_by(&Employee::salary).desc(), limit(2, offset(1)));
范围 Between Operator
测试值是否在值范围(包括边界)内的逻辑运算符。
注意:BETWEEN 可以在 SELECT、DELETE、UPDATE 和 REPLACE 语句的 WHERE 子句中使用。
// Syntax:
// test_expression BETWEEN low_expression AND high_expression
// SELECT DEPARTMENT_ID FROM departments
// WHERE manager_id
// BETWEEN 100 AND 200
auto rows = storage.select(&Department::id, where(between(&Department::managerId, 100, 200)));
// SELECT DEPARTMENT_ID FROM departments
// WHERE DEPARTMENT_NAME
// BETWEEN “D” AND “F”
auto rows = storage.select(&Department::id, where(between(&Department::dept, "D", "F")));
auto objects = storage.get_all<Department>(where(between(&Department::dept, "D", "F")));
在 In
值是否与列表或子查询中的任何值匹配,语法为:
表达式 [NOT] IN (value_list|子查询);
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE location_id=1700);
auto rows = storage.select(columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(in(&Employee::departmentId,
select(&Department::id, where(c(&Department::locationId) == 1700)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(in(&Employee::departmentId, ids)));
auto objects = storage.get_all<Employee>(where(in(&Employee::departmentId, {10,20,30} )));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id NOT IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(not_in(&Employee::departmentId, ids)));
auto objects = storage.get_all<Employee>(where(not_in(&Employee::departmentId, { 10,20,30 })));
// SELECT "Emp"."empno", "Emp"."ename", "Emp"."job", "Emp"."salary", "Emp"."deptno" FROM 'Emp' WHERE
// (("Emp"."ename", "Emp"."job", "Emp"."salary") IN (
// SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp'
// INTERSECT
// SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp' WHERE (("Emp"."job" = “Clerk”))))
auto rows = storage.select(columns
(&Employee::m_empno, &Employee::m_ename, &Employee::m_job, &Employee::m_salary, &Employee::m_deptno),
where(c(std::make_tuple( &Employee::m_ename, &Employee::m_job, &Employee::m_salary))
.in(intersect(
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary)),
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
where(c(&Employee::m_job) == "Clerk")
)))));
当然可以简化为:
// SELECT "Emp"."empno", "Emp"."ename", "Emp"."job", "Emp"."salary", "Emp"."deptno" FROM 'Emp'
// WHERE(("Emp"."ename", "Emp"."job", "Emp"."salary")
// IN(SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp' WHERE(("Emp"."job" = “Clerk”))))
auto rows = storage.select(columns(
&Employee::m_empno, &Employee::m_ename, &Employee::m_job, &Employee::m_salary, &Employee::m_deptno),
where(
in(std::make_tuple(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
where(c(&Employee::m_job) == "Clerk")))));
模糊 Like
匹配使用 2 个通配符的模式:% 和 _。
% 匹配 0 个或多个字符,而 _ 匹配任何字符。对于 ASCII 范围内的字符,比较不区分大小写;否则区分大小写。sensitive.
SELECT column_list FROM table_name WHERE column_1 LIKE pattern;
auto whereCondition = where(like(&User::name, "S%"));
auto users = storage.get_all<User>(whereCondition);
auto rows = storage.select(&User::id, whereCondition);
auto rows = storage.select(like("ototo", "ot_to"));
auto rows = storage.select(like(&User::name, "%S%a"));
auto rows = storage.select(like(&User::name, "^%a").escape("^"));
全局 Glob
- 类似于 like 运算符,但使用 UNIX 通配符,如下所示:
- 星号 () 匹配任意数量的字符(模式 Man 匹配以 Man 开头的字符串)
- 问号 (?) 只匹配一个字符(模式 Man?匹配以 Man 开头后跟任何字符的字符串)
- 列表通配符 [] 匹配括号内列表中的一个字符。例如,[abc] 匹配 a、b 或 c。
- 列表通配符可以使用 [a-zA-Z0-9] 中的范围
- 通过使用 ^,我们可以匹配除列表中的字符之外的任何字符([^0-9] 匹配任何非数字字符)。
auto rows = storage.select(columns(&Employee::lastName), where(glob(&Employee::lastName, "[^A-J]*")));
auto employees = storage.get_all<Employee>(where(glob(&Employee::lastName, "[^A-J]*")));
为空 IS NULL
// SELECT
// artists.ArtistId,
// albumId
// FROM
// artists
// LEFT JOIN albums ON albums.artistid = artists.artistid
// WHERE
// albumid IS NULL;
auto rows = storage.select(columns(&Artist::artistId, &Album::albumId),
left_join<Album>(on(c(&Album::artistId) == &Artist::artistId)),
where(is_null(&Album::albumId)));
处理列中的 NULL 值
// Transforming null values into real values
// SELECT COALESCE(comm,0), comm FROM EMP
auto rows = storage.select(columns(coalesce<double>(&Employee::m_commission, 0), &Employee::m_commission));
连接表
表表达式分为连接表表达式和非连接表表达式:
表表达式 ::= 连接表表达式 |非连接表表达式 连接表表达式 := 表引用 交叉连接表引用 |表引用 [自然] [连接类型] 连接表引用 [打开条件表达式] |使用(列逗号)] |(连接表表达式)
Table-expressions ::= join-table-expression | nonjoin-table-expression Join-table-expression := table-reference CROSS JOIN table-reference | table-reference [NATURAL] [join-type] JOIN table-reference [ON conditional-expression] | USING (column-commalist) ] | (join-table-expression)
SQLite join
在SQLite中,要从多个表中查询数据,您可以使用内部连接,左连接或交叉连接6。每个子句确定如何将一个表中的行“链接”到另一个表中的行。没有对右联接或完全外联接的显式支持。表达式 OUTER 是可选的,不会更改 JOIN 的定义。
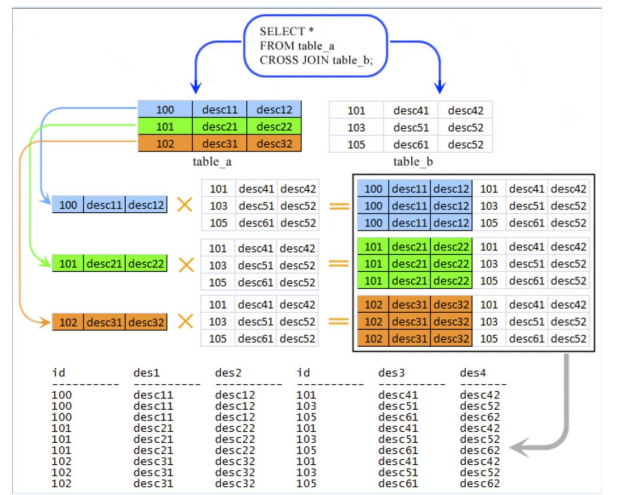
Cross join
交叉连接更准确地称为扩展笛卡尔积。如果 A 和 B 是 2 个表引用的求值中的表,则交叉连接 B 的计算结果为包含所有可能的行 R 的表,使得 R 是 A 中的行和 B 中的行的串联。实际上,A 交叉联接 B 联接表达式在语义上等效于以下选择表达式:
( SELECT A., B. FROM A,B )
其他联接 Other joins
表引用 [自然] [ 连接类型] 连接表引用 [ ON 条件表达式 | 使用(列逗号) ]
Table-reference [NATURAL] [ join-type] JOIN table-reference [ ON conditional-expression | using(column-commalist) ]
联接类型可以是以下任何一种
- INNER7 内部
- LEFT [OUTER] 左
- RIGHT [OUTER] 右
- FULL [OUTER] 完整
- UNION8 联合
具有以下限制:
- 自然和联盟不能同时指定
- 如果指定了 NATURAL 或 UNION,则不能指定 ON 子句或 USING 子句
- 如果既未指定 NATURAL 也未指定 UNION,则必须指定 ON 子句或 USING 子句
- 如果省略连接类型,则默认采用 INNER
重要的是要认识到,LEFT、RIGHT 和 FULL 中的 OUTER 对表达式的整体语义没有影响,因此是完全不必要的。左、右、满和 UNION 都与 NULL 有关,所以让我们先检查一下其他的:
- 表引用 连接表引用 条件表达式
- 表引用 JOIN 表引用使用 ( 列逗号)
- 表引用 自然连接表引用
情况 1: 等效于以下选择表达式,其中 cond 是条件表达式:(选择 A*., B.*从 A,B 其中 COND)
情况 2:让 USING 子句中的列的逗号为非限定符 C1、C2、..、Cn,那么它等效于具有以下 ON 子句的情况 1:ON A.C1 = B.C1 和 A.C2 = B.C2 和 ...A.Cn = B.Cn。
最后,情况 3 等效于情况 2,其中 USING 子句包含 A 和 B 中具有相同名称的所有列。
与 NULL 有关的连接(即外连接)
在 INNER 连接中,当我们尝试构造 2 个表 A 和 B 的普通连接时,任何与另一个表中没有行匹配的行(在相关连接条件下)都不会参与结果。在外连接中,这样的行参与结果:它只出现一次,如果这样的映射行确实存在,那么本来可以用另一个表中的值填充的列位置将改为用 null 填充。因此,外部连接在结果中保留不匹配的行,而内部连接排除它们。
A 和 B 的左外连接保留 A 中的行,而 B 中没有匹配的行。A 和 B 的右外连接,保留 B 中的行,而 A 中没有匹配的行。完全外部联接会保留两者。让我们分析一下左外连接的特定情况,因为其他情况是相似的: 我们有三个选项来编写左连接:
- 表引用 左连接 表引用 在条件表达式上
- 表引用 左连接表引用使用(列逗号)
- 表引用 自然左连接 表引用 案例 1 可以表示为以下 select 语句:
SELECT A., B. FROM A,B WHERE condition UNION ALL SELECT A.*, NULL, NULL, …,NULL FROM A WHERE A.pkey NOT IN ( SELECT A.pkey FROM A,B WHERE condition)
选择 A.*、B。*从 A,B 其中条件联合全部选择 A.*,NULL,NULL,...,空从 A 中 A.pkey 不在 ( 从 A,B 中选择 A.pkey where 条件)
这意味着 (a) 相应的内部连接和 (b) 从内部连接中排除的行集合的 UNION ALL,其中 NULL 列的数量与 B 中的列数一样多。
对于情况 2,设 USING 子句中列的逗号符为 C1、C2,...,Cn,所有 Ci 均为非限定符,并标识 A 和 B 的公共列。然后,该案例与条件形式为以下形式的案例 1 相同(A.C1 = B.C1 AND A.C2 = B.A2, ..., A.Cn = B.Cn)
对于案例 3,用于案例 2 的列的逗号是 A 和 B 中所有公共列的集合。
左连接示例:

// SELECT
// artists.ArtistId,
// albumId
// FROM
// artists
// LEFT JOIN albums ON albums.artistid = artists.artistid
// ORDER BY
// albumid;
auto rows = storage.select(columns(&Artist::artistId, &Album::albumId),
left_join<Album>(on(c(&Album::artistId) == &Artist::artistId)),
order_by(&Album::albumId));
内联接示例
// SELECT
// trackid,
// name,
// title
// FROM
// tracks
// INNER JOIN albums ON albums.albumid = tracks.albumid;
auto innerJoinRows0 = storage.select(columns(&Track::trackId, &Track::name, &Album::title),
inner_join<Album>(on(
c(&Track::albumId) == &Album::albumId)));
在此示例中,曲目表中的每一行都根据 on 子句与专辑表中的一行匹配。当此子句为 true 时,相应表中的列将显示为“扩展行” – 我们实际上是使用连接表中的属性创建一个匿名类型。这些表之间的关系是每 1 张专辑 N 首曲目。根据 on 子句,具有相同专辑 ID 的所有 N 首曲目都与具有匹配列的 1 张专辑连接。
自然连接示例
// SELECT doctor_id,doctor_name,degree,patient_name,vdate
// FROM doctors
// NATURAL JOIN visits
// WHERE doctors.degree="MD";
auto rows = storage.select(
columns(&Doctor::doctor_id, &Doctor::doctor_name, &Doctor::degree, &Visit::patient_name, &Visit::vdate),
natural_join<Visit>(),
where(c(&Doctor::degree) == "MD"));
// SELECT doctor_id,doctor_name,degree,spl_descrip,patient_name,vdate
// FROM doctors
// NATURAL JOIN speciality
// NATURAL JOIN visits
// WHERE doctors.degree='MD';
auto rows = storage.select(columns(&Doctor::doctor_id,
&Doctor::doctor_name,
&Doctor::degree,
&Speciality::spl_descrip,
&Visit::patient_name,
&Visit::vdate),
natural_join<Speciality>(),
natural_join<Visit>(),
where(c(&Doctor::degree) == "MD"));
自链接 Self join
// SELECT m.FirstName || ' ' || m.LastName,
// employees.FirstName || ' ' || employees.LastName
// FROM employees
// INNER JOIN employees m
// ON m.ReportsTo = employees.EmployeeId
using als = alias_m<Employee>;
auto firstNames = storage.select(
columns(c(alias_column<als>(&Employee::firstName)) || " " || c(alias_column<als>(&Employee::lastName)),
c(&Employee::firstName) || " " || c(&Employee::lastName)),
inner_join<als>(on(alias_column<als>(&Employee::reportsTo) == c(&Employee::employeeId))));
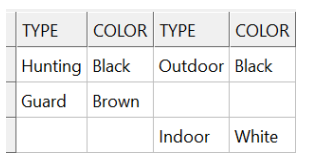
完全外部联接 Full outer join
虽然SQLite不支持完全外部连接,但模拟它非常容易。以这 2 个类/表为例,插入一些数据并执行“完全外部连接”:
struct Dog
{
std::optional<std::string> type;
std::optional<std::string> color;
};
struct Cat
{
std::optional<std::string> type;
std::optional<std::string> color;
};
using namespace sqlite_orm;
auto storage = make_storage(
{ "full_outer.sqlite" },
make_table("Dogs", make_column("type", &Dog::type), make_column("color", &Dog::color)),
make_table("Cats", make_column("type", &Cat::type), make_column("color", &Cat::color)));
storage.sync_schema();
storage.remove_all<Dog>();
storage.remove_all<Cat>();
storage.insert(into<Dog>(), columns(&Dog::type, &Dog::color), values(
std::make_tuple("Hunting", "Black"), std::make_tuple("Guard", "Brown")));
storage.insert(into<Cat>(), columns(&Cat::type, &Cat::color), values(
std::make_tuple("Indoor", "White"), std::make_tuple("Outdoor", "Black")));
// FULL OUTER JOIN simulation:
// SELECT d.type,
// d.color,
// c.type,
// c.color
// FROM dogs d
// LEFT JOIN cats c USING(color)
// UNION ALL
// SELECT d.type,
// d.color,
// c.type,
// c.color
// FROM cats c
// LEFT JOIN dogs d USING(color)
// WHERE d.color IS NULL;
auto rows = storage.select(
union_all(select(columns(&Dog::type, &Dog::color, &Cat::type, &Cat::color),
left_join<Cat>(using_(&Cat::color))),
select(columns(&Dog::type, &Dog::color, &Cat::type, &Cat::color), from<Cat>(),
left_join<Dog>(using_(&Dog::color)), where(is_null(&Dog::color)))));
对数据进行分组
group by 子句是 select 语句的可选子句,它使我们能够按一列或多列的值将选定的一组行放入摘要行中。它为每个组返回一行,并且可以应用聚合函数,例如 MIN,MAX,SUM,COUNT 或 AVG – 或者您自己sqlite_orm9编程的函数!
语法为:SELECT column_1, aggregate_function(column_2) FROM table GROUP BY column_1, column_2;
分组 Group by
// If you want to know the total amount of salary on each customer, then GROUP BY query would be as follows:
// SELECT NAME, SUM(SALARY)
// FROM COMPANY
// GROUP BY NAME;
auto salaryName = storage.select(columns(&Employee::name, sum(&Employee::salary)), group_by(&Employee::name));
Group by date example:
// SELECT (STRFTIME(“%Y”, "Invoices"."invoiceDate")) AS InvoiceYear,
// (COUNT("Invoices"."id")) AS InvoiceCount FROM 'Invoices' GROUP BY InvoiceYear
// ORDER BY InvoiceYear DESC
struct InvoiceYearAlias : alias_tag {
static const std::string& get() {
static const std::string res = "INVOICE_YEAR";
return res;
}
};
auto statement = storage.select(columns(as<InvoiceYearAlias>(strftime("%Y", &Invoice::invoiceDate)),
as<InvoiceCountAlias>(count(&Invoice::id))), group_by(get<InvoiceYearAlias>()),
order_by(get<InvoiceYearAlias>()).desc());
拥有 Having
While the where clause restricts the rows selected, the having clause selects data at the group level. For instance:
// SELECT NAME, SUM(SALARY)
// FROM COMPANY
// WHERE NAME is like "%l%"
// GROUP BY NAME
// HAVING SUM(SALARY) > 10000
auto namesWithHigherSalaries = storage.select(columns(&Employee::name, sum(&Employee::salary)),
where(like(&Employee::name, "%l%")),
group_by(&Employee::name).having(sum(&Employee::salary) > 10000));
设置运算符 Set operators
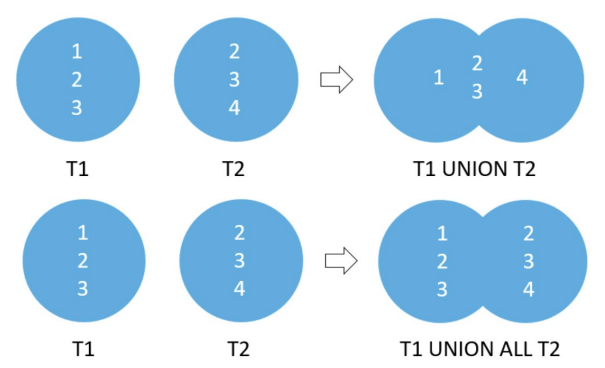
并联 Union
- UNION 和 JOIN 之间的区别在于,JOIN 子句合并来自多个相关表的列,而 UNION 组合来自多个相似表的行。UNION 运算符删除重复的行,而 UNION ALL 运算符不会。使用 UNION 的规则如下:
- 所有查询中的列数必须相同
- 相应的列必须具有兼容的数据类型
- 第一个查询的列名确定组合结果集的列名
- 分组依据和包含子句应用于每个单独的查询,而不是最终结果集
- 排序依据应用于组合结果集,而不是单个结果集中
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID;
auto rows = storage.select(
union_(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId))))));
Union all:
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION ALL
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
auto rows = storage.select(
union_all(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))))));
Union ALL & order by:
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION ALL
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// ORDER BY NAME
auto rows = storage.select(
union_all(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId))),
order_by(&Employee::name))));
将一个结果集堆叠在另一个结果集之上
// SELECT "Dept"."deptname" AS ENAME_AND_DNAME, "Dept"."deptno" FROM 'Dept'
// UNION ALL
// SELECT (QUOTE("------------------")), NULL
// UNION ALL
// SELECT "Emp"."ename" AS ENAME_AND_DNAME, "Emp"."deptno" FROM 'Emp'
auto rows = storage.select(
union_all(
select(columns(as<NamesAlias>(&Department::m_deptname), as_optional(&Department::m_deptno))),
select(union_all(
select(columns(quote("--------------------"), std::optional<int>())),
select(columns(as<NamesAlias>(&Employee::m_ename),
as_optional(&Employee::m_deptno))))))));
除了 Except
比较 2 个查询的结果集,并保留仅在第一个结果集中存在的行。这些是规则:
- 每个查询中的列数必须相同
- 列的顺序及其类型必须具有可比性
查找dept_master中的所有dept_id,但不是emp_master:
// SELECT dept_id
// FROM dept_master
// EXCEPT
// SELECT dept_id
// FROM emp_master
auto rows = storage.select(except(select(&DeptMaster::deptId), select(&EmpMaster::deptId)));
Find all artists ids of artists who do not have any album in the albums table:
// SELECT ArtistId FROM artists EXCEPT SELECT ArtistId FROM albums;
auto rows = storage.select(except(select(&Artist::m_id), select(&Album::m_artist_id)));
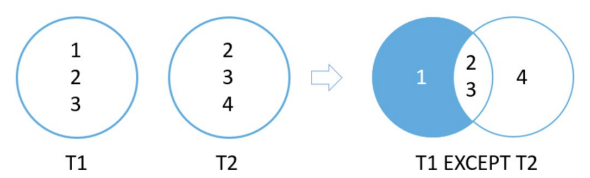
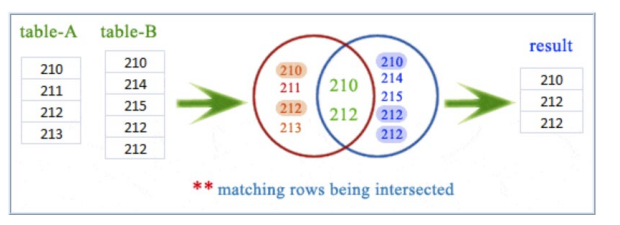
相交 Intersect
比较 2 个查询的结果集,并返回两个查询输出的不同行。语法:SELECT select_list1 FROM table1 INTERSECT SELECT select_list2 FROM table2
- 这些是规则:
- 每个查询中的列数必须相同
- 列的顺序及其类型必须具有可比性
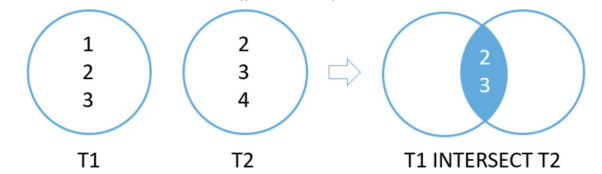
// SELECT dept_id
// FROM dept_master
// INTERSECT
// SELECT dept_id
// FROM emp_master
auto rows = storage.select(intersect(select(&DeptMaster::deptId), select(&EmpMaster::deptId)));
To find the customers who have invoices:
SELECT CustomerId FROM customers INTERSECT SELECT CustomerId FROM invoices ORDER BY CustomerId;
子查询 Subquery
子查询 Subquery
子查询是另一个语句中的嵌套 SELECT,例如:SELECT column_1 FROM table_1 WHERE column_1 = ( SELECT column_1 FROM table_2 );
// SELECT first_name, last_name, salary
// FROM employees
// WHERE salary >(
// SELECT salary
// FROM employees
// WHERE first_name='Alexander');
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::salary),
where(greater_than(&Employee::salary,
select(&Employee::salary,
where(is_equal(&Employee::firstName, "Alexander"))))));
// SELECT employee_id,first_name,last_name,salary
// FROM employees
// WHERE salary > (SELECT AVG(SALARY) FROM employees);
auto rows = storage.select(columns(
&Employee::id, &Employee::firstName, &Employee::lastName, &Employee::salary),
where(greater_than(&Employee::salary,
select(avg(&Employee::salary)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE location_id=1700);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(in(
&Employee::departmentId,
select(&Department::id, where(c(&Department::locationId) == 1700)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(in(&Employee::departmentId, ids)));
// SELECT * FROM employees
// WHERE department_id IN (10,20,30)
auto objects = storage.get_all<Employee>(where(in(&Employee::departmentId, {10,20,30} )));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id NOT IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE manager_id
// BETWEEN 100 AND 200);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(not_in(&Employee::departmentId,
select(&Department::id, where(between(&Department::managerId, 100, 200))))));
// SELECT 'e'."LAST_NAME", 'e'."SALARY", 'e'."DEPARTMENT_ID" FROM 'employees' 'e'
// WHERE (('e'."SALARY" > (SELECT (AVG("employees"."SALARY")) FROM 'employees',
// 'employees' e WHERE (("employees"."DEPARTMENT_ID" = 'e'."DEPARTMENT_ID")))))
using als = alias_e<Employee>;
auto rows = storage.select(
columns(alias_column<als>(&Employee::lastName),
alias_column<als>(&Employee::salary),
alias_column<als>(&Employee::departmentId)),
from<als>(),
where(greater_than(
alias_column<als>(&Employee::salary),
select(avg(&Employee::salary),
where(is_equal(&Employee::departmentId, alias_column<als>(&Employee::departmentId)))))));
// SELECT first_name, last_name, employee_id, job_id
// FROM employees
// WHERE 1 <=
// (SELECT COUNT(*) FROM Job_history
// WHERE employee_id = employees.employee_id);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::id, &Employee::jobId), from<Employee>(),
where(lesser_or_equal(
1,
select(count<JobHistory>(), where(is_equal(&Employee::id, &JobHistory::employeeId))))));
SELECT albumid, title, (SELECT count(trackid) FROM tracks WHERE tracks.AlbumId = albums.AlbumId) tracks_count FROM albums ORDER BY tracks_count DESC;
存在 Exists
检查子查询是否返回任何行的逻辑运算符。子查询是返回 0 行或更多行的 select 语句。语法:
存在(子查询)
// SELECT agent_code,agent_name,working_area,commission
// FROM agents
// WHERE exists
// (SELECT *
// FROM customer
// WHERE grade=3 AND agents.agent_code=customer.agent_code)
// ORDER BY commission;
auto rows = storage.select(columns(&Agent::code, &Agent::name, &Agent::workingArea, &Agent::comission),
from<Agent>(),
where(exists(select(asterisk<Customer>(), from<Customer>(),
where(is_equal(&Customer::grade, 3)
and is_equal(&Agent::code, &Customer::agentCode))))),
order_by(&Agent::comission));
// SELECT cust_code, cust_name, cust_city, grade
// FROM customer
// WHERE grade=2 AND EXISTS
// (SELECT COUNT(*)
// FROM customer
// WHERE grade=2
// GROUP BY grade
// HAVING COUNT(*)>2);
auto rows = storage.select(columns(&Customer::code, &Customer::name, &Customer::city, &Customer::grade),
where(is_equal(&Customer::grade, 2)
and exists(select(count<Customer>(), where(is_equal(&Customer::grade, 2)),
group_by(&Customer::grade),
having(greater_than(count(), 2))))));
// SELECT "orders"."AGENT_CODE", "orders"."ORD_NUM", "orders"."ORD_AMOUNT", "orders"."CUST_CODE", 'c'."PAYMENT_AMT"
// FROM 'orders' INNER JOIN 'customer' 'c' ON('c'."AGENT_CODE" = "orders"."AGENT_CODE")
// WHERE(NOT(EXISTS
// (
// SELECT 'd'."AGENT_CODE" FROM 'customer' 'd' WHERE((('c'."PAYMENT_AMT" = 7000) AND('d'."AGENT_CODE" =
// 'c'."AGENT_CODE")))))
// )
// ORDER BY 'c'."PAYMENT_AMT"
using als = alias_c<Customer>;
using als_2 = alias_d<Customer>;
double amount = 2000;
auto where_clause = select(alias_column<als_2>(&Customer::agentCode), from<als_2>(),
where(is_equal(alias_column<als>(&Customer::paymentAmt), std::ref(amount)) and
(alias_column<als_2>(&Customer::agentCode) == c(alias_column<als>(&Customer::agentCode)))));
金额 = 7000;
auto rows = storage.select(columns(
&Order::agentCode, &Order::num, &Order::amount,&Order::custCode,alias_column<als>(&Customer::paymentAmt)),
from<Order>(),
inner_join<als>(on(alias_column<als>(&Customer::agentCode) == c(&Order::agentCode))),
where(not exists(where_clause)), order_by(alias_column<als>(&Customer::paymentAmt)));
更多查询技术
Case
我们可以使用 CASE 表达式向查询添加条件逻辑(C++ 中的 if else 或 switch 语句)。有两种语法可用,其中一种都可以具有列别名(见下文)。
CASE case_expression
WHEN case_expression = when_expression_1 THEN result_1
WHEN case_expression = when_expression_2 THEN result_2
...
[ ELSE result_else ]
END
// SELECT CASE "users"."country" WHEN “USA” THEN “Domestic” ELSE “Foreign” END
// FROM 'users' ORDER BY "users"."last_name" , "users"."first_name"
auto rows = storage.select(columns(
case_<std::string>(&User::country)
.when("USA", then("Domestic"))
.else_("Foreign").end()),
multi_order_by(order_by(&User::lastName), order_by(&User::firstName)));
CASE
WHEN when_expression_1 THEN result_1
WHEN when_expression_2 THEN result_2
...
[ ELSE result_else ]
END
// SELECT ID, NAME, MARKS,
// CASE
// WHEN MARKS >=80 THEN 'A+'
// WHEN MARKS >=70 THEN 'A'
// WHEN MARKS >=60 THEN 'B'
// WHEN MARKS >=50 THEN 'C'
// ELSE 'Sorry!! Failed'
// END
// FROM STUDENT;
auto rows = storage.select(columns(&Student::id,
&Student::name,
&Student::marks,
case_<std::string>()
.when(greater_or_equal(&Student::marks, 80), then("A+"))
.when(greater_or_equal(&Student::marks, 70), then("A"))
.when(greater_or_equal(&Student::marks, 60), then("B"))
.when(greater_or_equal(&Student::marks, 50), then("C"))
.else_("Sorry!! Failed")
.end()));
列和表的别名
对于表:
// SELECT C.ID, C.NAME, C.AGE, D.DEPT
// FROM COMPANY AS C, DEPARTMENT AS D
// WHERE C.ID = D.EMP_ID;
using als_c = alias_c<Employee>;
using als_d = alias_d<Department>;
auto rowsWithTableAliases = storage.select(columns(
alias_column<als_c>(&Employee::id),
alias_column<als_c>(&Employee::name),
alias_column<als_c>(&Employee::age),
alias_column<als_d>(&Department::dept)),
where(is_equal(alias_column<als_c>(&Employee::id), alias_column<als_d>(&Department::empId))));
对于列:
struct EmployeeIdAlias : alias_tag {
static const std::string& get() {
static const std::string res = "COMPANY_ID";
return res;
}
};
struct CompanyNameAlias : alias_tag {
static const std::string& get() {
static const std::string res = "COMPANY_NAME";
return res;
}
};
// SELECT COMPANY.ID as COMPANY_ID, COMPANY.NAME AS COMPANY_NAME, COMPANY.AGE, DEPARTMENT.DEPT
// FROM COMPANY, DEPARTMENT
// WHERE COMPANY_ID = DEPARTMENT.EMP_ID;
auto rowsWithColumnAliases = storage.select(columns(
as<EmployeeIdAlias>(&Employee::id),
as<CompanyNameAlias>(&Employee::name),
&Employee::age,
&Department::dept),
where(is_equal(get<EmployeeIdAlias>(), &Department::empId)));
For columns and tables:
// SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT
// FROM COMPANY AS C, DEPARTMENT AS D
// WHERE C.ID = D.EMP_ID;
auto rowsWithBothTableAndColumnAliases = storage.select(columns(
as<EmployeeIdAlias>(alias_column<als_c>(&Employee::id)),
as<CompanyNameAlias>(alias_column<als_c>(&Employee::name)),
alias_column<als_c>(&Employee::age),
alias_column<als_d>(&Department::dept)),
where(is_equal(alias_column<als_c>(&Employee::id), alias_column<als_d>(&Department::empId))));
将别名应用于案例
struct GradeAlias : alias_tag {
static const std::string& get() {
static const std::string res = "Grade";
return res;
}
};
// SELECT ID, NAME, MARKS,
// CASE
// WHEN MARKS >=80 THEN 'A+'
// WHEN MARKS >=70 THEN 'A'
// WHEN MARKS >=60 THEN 'B'
// WHEN MARKS >=50 THEN 'C'
// ELSE 'Sorry!! Failed'
// END as 'Grade'
// FROM STUDENT;
auto rows = storage.select(columns(
&Student::id,
&Student::name,
&Student::marks,
as<GradeAlias>(case_<std::string>()
.when(greater_or_equal(&Student::marks, 80), then("A+"))
.when(greater_or_equal(&Student::marks, 70), then("A"))
.when(greater_or_equal(&Student::marks, 60), then("B"))
.when(greater_or_equal(&Student::marks, 50), then("C"))
.else_("Sorry!! Failed")
.end())));
更改数据
在表中插入单行
INSERT INTO table (column1,column2 ,..) VALUES( value1, value2 ,...);
storage.insert(into<Invoice>(), columns(
&Invoice::id, &Invoice::customerId, &Invoice::invoiceDate),
values(std::make_tuple(1, 1, date("now")))));
插入对象
struct User {
int id; // primary key
std::string name;
std::vector<char> hash; // binary format
};
User alex{
0,
"Alex",
{0x10, 0x20, 0x30, 0x40},
};
alex.id = storage.insert(alex); // inserts all non primary key columns, returns primary key when integral
插入多行
storage.insert(into<Invoice>(),
columns(&Invoice::id, &Invoice::customerId, &Invoice::invoiceDate),
values(std::make_tuple(1, 1, date("now")),
std::make_tuple(2, 1, date("now", "+1 year")),
std::make_tuple(3, 1, date("now")),
std::make_tuple(4, 1, date("now", "+1 year"))));
通过容器插入多个对象
如果我们想插入或替换一组持久原子,我们可以将它们插入容器中,并通过存储类型的insert_range或replace_range方法为所需对象范围的开头和结尾提供迭代器。例如:
std::vector<Department> des =
{
Department{10, "Accounting", "New York"},
Department{20, "Research", "Dallas"},
Department{30, "Sales", "Chicago"},
Department{40, "Operations", "Boston"}
};
std::vector<EmpBonus> bonuses =
{
EmpBonus{-1, 7369, "14-Mar-2005", 1},
EmpBonus{-1, 7900, "14-Mar-2005", 2},
EmpBonus{-1, 7788, "14-Mar-2005", 3}
};
storage.replace_range(des.begin(), des.end());
storage.insert_range(bonuses.begin(), bonuses.end());
回想一下,插入 like 语句不会设置主键,而替换 like 语句会复制包括主键在内的所有列。这应该可以解释为什么我们选择替换部门,因为它们具有明确的主键值,以及为什么我们选择插入奖励让数据库生成主键值。
插入多行(如果主键已存在,则变为更新)
// INSERT INTO COMPANY(ID, NAME, AGE, ADDRESS, SALARY)
// VALUES (3, 'Sofia', 26, 'Madrid', 15000.0)
// (4, 'Doja', 26, 'LA', 25000.0)
// ON CONFLICT(ID) DO UPDATE SET NAME = excluded.NAME,
// AGE = excluded.AGE,
// ADDRESS = excluded.ADDRESS,
// SALARY = excluded.SALARY
storage.insert(
into<Employee>(),
columns(&Employee::id, &Employee::name, &Employee::age, &Employee::address, &Employee::salary),
values(
std::make_tuple(3, "Sofia", 26, "Madrid", 15000.0),
std::make_tuple(4, "Doja", 26, "LA", 25000.0)),
on_conflict(&Employee::id)
.do_update(
set(c(&Employee::name) = excluded(&Employee::name),
c(&Employee::age) = excluded(&Employee::age),
c(&Employee::address) = excluded(&Employee::address),
c(&Employee::salary) = excluded(&Employee::salary))));
仅插入某些列(前提是其余列具有default_values、可为空、自动增量或生成):
// INSERT INTO Invoices("customerId") VALUES(2), (4), (8)
storage.insert(into<Invoice>(),
columns(&Invoice::customerId),
values(
std::make_tuple(2),
std::make_tuple(4),
std::make_tuple(8)));
// INSERT INTO 'Invoices' ("customerId") VALUES (NULL)
Invoice inv{ -1, 1, std::nullopt };
storage.insert(inv, columns(&Invoice::customerId));
从选择插入 – 获取 rowid(因为主键是整数)
// INSERT INTO users SELECT "user_backup"."id", "user_backup"."name", "user_backup"."hash" FROM 'user_backup'
storage.insert(into<User>(),
select(columns(&UserBackup::id, &UserBackup::name, &UserBackup::hash))));
auto r = storage.select(last_insert_rowid());
插入默认值:
storage.insert(into<Artist>(), default_values());
-
-
SQLITE 中的非标准扩展
适用于唯一、非空、检查和PRIMARY_KEY约束,但不适用于外键约束。对于插入和更新命令10,语法为 INSERT OR Y 或 UPDATE OR Y,其中 Y 可以是以下任何算法,默认冲突解决算法为 ABORT:
- 反转:
- 中止当前语句并出现SQLITE_CONSTRAINT错误并回滚当前事务;如果没有活动事务,则表现为 ABORT
- 流产
- 当发生约束冲突时,返回SQLITE_CONSTRAINT错误,当前 SQL 语句回退它所做的任何更改,但由同一事务中的先前语句引起的更改将保留,并且事务保持活动状态。这是默认的冲突解决算法。
- 失败
- 与中止相同,只是它不会回退当前 SQL 语句的先前更改...外键约束导致 ABORT
- 忽视
- 跳过包含约束冲突的一行,并继续处理 SQL 语句的后续行,就好像没有出错一样:正常插入或更新具有约束冲突的行之前和之后的行...外键约束冲突导致 ABORT 行为
- 取代
- 当 UNIQUE 或 PRIMARY KEY 类型发生约束冲突时,在插入或更新当前行之前,将删除导致冲突的预先存在的行,并且命令将继续正常执行。如果发生 NOT NULL 冲突,则 NULL 将替换为该列的默认值(如果存在),否则使用 ABORT 算法。对于 CHECK 或外键冲突,该算法的工作方式类似于 ABORT。对于已删除的行,当且仅当启用了递归触发器11时,才会触发删除触发器(如果有)。
-
auto rows = storage.insert(or_abort(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_fail(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_ignore(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_replace(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_rollback(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
更新 Update
这使我们能够更新表中现有行的数据。一般语法是这样的:
UPDATE table SET column_1 = new_value_1, column_2 = new_value_2 WHERE search_condition;
更新多行
// UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00 WHERE AGE < 30
storage.update_all(set(
c(&Employee::address) = "Texas", c(&Employee::salary) = 20000.00),
where(c(&Employee::age) < 30));
// UPDATE contacts
// SET phone = REPLACE12(phone, '410', '+1-410')
storage.update_all(set(
c(&Contact::phone) = replace(&Contact::phone, "410", "+1-410")));
更新一行
// UPDATE products
// SET quantity = 5 WHERE id = 1;
storage.update_all(set(
c(&Product::quantity) = 5),
where(c(&Product::id) == 1));
更新对象
如果学生存在,则更新,否则插入:
if(storage.count<Student>(where(c(&Student::id) == student.id))) {
storage.update(student);
} else {
studentId = storage.insert(student); // returns primary key
}
auto employee6 = storage.get<Employee>(6);
// UPDATE 'COMPANY' SET "NAME" = val1, "AGE" = val2, "ADDRESS" = “Texas” , "SALARY" = val4 WHERE "ID" = 6
employee6.address = "Texas";
storage.update(employee6); // actually this call updates all non-primary-key columns' values to passed object's
// fields
删除语法
由于删除是一个C++关键字,因此在sqlite_orm中使用删除和remove_all。DELETE 的一般语法是 SQL 格式:
DELETE FROM table-name [WHERE expr]
删除满足条件的行
// DELETE FROM artist WHERE artistname = 'Sammy Davis Jr.';
storage.remove_all<Artist>(
where(c(&Artist::artistName) == "Sammy Davis Jr."));
删除特定类型的所有对象
// DELETE FROM Customer
storage.remove_all<Customer>();
通过提供主键删除某个对象
// DELETE FROM Customer WHERE id = 1;
storage.remove<Customer>(1);
取代 Replace
如果我们想设置主键列以及其余列,我们需要使用 replace 而不是 insert:
User john{
2,
"John",
{0x10, 0x20, 0x30, 0x40},
};
// REPLACE INTO 'Users ("id", "name", "hash") VALUES (2, “John”, {0x10, 0x20, 0x30, 0x40})
storage.replace(john);
Transactions
Transactions
SQLite 是事务性的,因为所有更改和查询都是原子的、一致的、隔离的和持久的,更广为人知的是 ACID:
- 原子:更改不能分解为较小的更改:提交事务要么应用其中的每个语句,要么根本不应用。
- 一致:数据必须满足交易前后的所有验证规则
- 隔离:假设 2 个事务同时执行,尝试修改相同的数据。其中之一必须等到另一个完成才能保持隔离
- 持久性:考虑一个事务提交,但随后程序崩溃或操作系统崩溃或计算机电源故障。事务必须确保即使在这种情况下,提交的更改也会持续存在。
Sqlite有一些编译指示,可以准确定义这些事务的完成方式以及它们提供的持久性级别。为了更好的耐用性,性能较低。请参阅PRAGMA架构。journal_mode SQLite 支持的 Pragma 语句...和预写日志记录 (sqlite.org) 进行详细讨论。
注意:如果在事务中完成,则对数据库的更改速度更快,如下所示:
storage.begin_transaction();
storage.replace(Employee{
1,
"Adams",
"Andrew",
"General Manager",
{},
"1962-02-18 00:00:00",
"2002-08-14 00:00:00",
"11120 Jasper Ave NW",
"Edmonton",
"AB",
"Canada",
"T5K 2N1",
"+1 (780) 428-9482",
"+1 (780) 428-3457",
"andrew@chinookcorp.com",
});
storage.replace(Employee{
2,
"Edwards",
"Nancy",
"Sales Manager",
std::make_unique<int>(1),
"1958-12-08 00:00:00",
"2002-05-01 00:00:00",
"825 8 Ave SW",
"Calgary",
"AB",
"Canada",
"T2P 2T3",
"+1 (403) 262-3443",
"+1 (403) 262-3322",
"nancy@chinookcorp.com",
});
storage.commit(); // or storage.rollback();
storage.transaction([&storage] {
storage.replace(Student{1, "Shweta", "shweta@gmail.com", 80});
storage.replace(Student{2, "Yamini", "rani@gmail.com", 60});
storage.replace(Student{3, "Sonal", "sonal@gmail.com", 50});
return true; // commits
});
注意:使用事务防护实现 RAII 习语
auto countBefore = storage.count<Object>();
try {
auto guard = storage.transaction_guard();
storage.insert(Object{0, "John"});
storage.get<Object>(-1); // throws exception!
REQUIRE(false);
} catch(...) {
auto countNow = storage.count<Object>();
REQUIRE(countBefore == countNow);
}
auto countBefore = storage.count<Object>();
try {
auto guard = storage.transaction_guard();
storage.insert(Object{0, "John"});
guard.commit();
storage.get<Object>(-1); // throws exception but transaction is not rolled back!
REQUIRE(false);
} catch(...) {
auto countNow = storage.count<Object>();
REQUIRE(countNow == countBefore + 1);
}
Core functions
// SELECT name, LENGTH(name)
// FROM marvel
auto namesWithLengths = storage.select(
columns(&MarvelHero::name,
length(&MarvelHero::name))); // namesWithLengths is std::vector<std::tuple<std::string, int>>
// SELECT ABS(points)
// FROM marvel
auto absPoints = storage.select(
abs(&MarvelHero::points)); // std::vector<std::unique_ptr<int>>
cout << "absPoints: ";
for(auto& value: absPoints)
{
if(value) {
cout << *value;
} else {
cout << "null";
}
cout << " ";
}
cout << endl;
// SELECT LOWER(name)
// FROM marvel
auto lowerNames = storage.select(
lower(&MarvelHero::name));
// SELECT UPPER(abilities)
// FROM marvel
auto upperAbilities = storage.select(
upper(&MarvelHero::abilities));
storage.transaction([&] {
storage.remove_all<MarvelHero>();
{ // SELECT changes()
auto rowsRemoved = storage.select(changes()).front();
cout << "rowsRemoved = " << rowsRemoved << endl;
assert(rowsRemoved == storage.changes());
}
{ // SELECT total_changes()
auto rowsRemoved = storage.select(total_changes()).front();
cout << "rowsRemoved = " << rowsRemoved << endl;
assert(rowsRemoved == storage.changes());
}
return false; // rollback
});
// SELECT CHAR(67, 72, 65, 82)
auto charString = storage.select(
char_(67, 72, 65, 82)).front();
cout << "SELECT CHAR(67,72,65,82) = *" << charString << "*" << endl;
// SELECT LOWER(name) || '@marvel.com'
// FROM marvel
auto emails = storage.select(
lower(&MarvelHero::name) || c("@marvel.com"));
// SELECT TRIM(' TechOnTheNet.com ')
auto string = storage.select(
trim(" TechOnTheNet.com ")).front();
// SELECT TRIM('000123000', '0')
storage.select(
trim("000123000", "0")).front()
// SELECT * FROM marvel ORDER BY RANDOM()
for(auto& hero: storage.iterate<MarvelHero>(order_by(sqlite_orm::random()))) {
cout << "hero = " << storage.dump(hero) << endl;
}
NOTE: Use iterate for large result sets because it does not load all the rows into memory
// SELECT ltrim(' TechOnTheNet.com is great!');
storage.select(ltrim(" TechOnTheNet.com is great!")).front();
Core functions can be used within prepared statements:
auto lTrimStatement = storage.prepare(select(
ltrim("000123", "0")));
// SELECT ltrim('123123totn', '123');
get<0>(lTrimStatement) = "123123totn";
get<1>(lTrimStatement) = "123";
cout << "ltrim('123123totn', '123') = " << storage.execute(lTrimStatement).front() << endl;
// SELECT rtrim('TechOnTheNet.com ');
cout << "rtrim('TechOnTheNet.com ') = *" << storage.select(rtrim("TechOnTheNet.com ")).front() << "*" << endl;
// SELECT rtrim('123000', '0');
cout << "rtrim('123000', '0') = *" << storage.select(rtrim("123000", "0")).front() << "*" << endl;
// SELECT coalesce(NULL,20);
cout << "coalesce(NULL,20) = " << storage.select(coalesce<int>(std::nullopt, 20)).front() << endl;
cout << "coalesce(NULL,20) = " << storage.select(coalesce<int>(nullptr, 20)).front() << endl;
// SELECT substr('SQLite substr', 8);
cout << "substr('SQLite substr', 8) = " << storage.select(substr("SQLite substr", 8)).front() << endl;
// SELECT substr('SQLite substr', 1, 6);
cout << "substr('SQLite substr', 1, 6) = " << storage.select(substr("SQLite substr", 1, 6)).front() << endl;
// SELECT hex(67);
cout << "hex(67) = " << storage.select(hex(67)).front() << endl;
// SELECT quote('hi')
cout << "SELECT quote('hi') = " << storage.select(quote("hi")).front() << endl;
// SELECT hex(randomblob(10))
cout << "SELECT hex(randomblob(10)) = " << storage.select(hex(randomblob(10))).front() << endl;
// SELECT instr('something about it', 't')
cout << "SELECT instr('something about it', 't') = " << storage.select(instr("something about it", "t")).front();
struct o_pos : alias_tag {
static const std::string& get() {
static const std::string res = "o_pos";
return res;
}
};
// SELECT name, instr(abilities, 'o') o_pos
// FROM marvel
// WHERE o_pos > 0
auto rows = storage.select(columns(
&MarvelHero::name, as<o_pos>(instr(&MarvelHero::abilities, "o"))),
where(greater_than(get<o_pos>(), 0)));
// SELECT replace('AA B CC AAA','A','Z')
cout << "SELECT replace('AA B CC AAA','A','Z') = " << storage.select(replace("AA B CC AAA", "A", "Z")).front();
// SELECT replace('This is a cat','This','That')
cout << "SELECT replace('This is a cat','This','That') = "
<< storage.select(replace("This is a cat", "This", "That")).front() << endl;
// SELECT round(1929.236, 2)
cout << "SELECT round(1929.236, 2) = " << storage.select(round(1929.236, 2)).front() << endl;
// SELECT round(1929.236, 1)
cout << "SELECT round(1929.236, 1) = " << storage.select(round(1929.236, 1)).front() << endl;
// SELECT round(1929.236)
cout << "SELECT round(1929.236) = " << storage.select(round(1929.236)).front() << endl;
// SELECT unicode('A')
cout << "SELECT unicode('A') = " << storage.select(unicode("A")).front() << endl;
// SELECT typeof(1)
cout << "SELECT typeof(1) = " << storage.select(typeof_(1)).front() << endl;
// SELECT firstname, lastname, IFNULL(fax, 'Call:' || phone) fax
// FROM customers ORDER BY firstname
auto rows = storage.select(columns(
&Customer::firstName, &Customer::lastName,
ifnull<std::string>(&Customer::fax, "Call:" || c(&Customer::phone))),
order_by(&Customer::firstName));
cout << "SELECT last_insert_rowid() = " << storage.select(last_insert_rowid()).front() << endl;
数据定义
Sqlite 数据类型
SQLITE 使用动态类型系统:存储在列中的值确定其数据类型,而不是列的数据类型。您甚至可以在不指定数据类型的情况下声明列。但是,sqlite_orm创建的列确实具有声明的数据类型。SQLite 提供了我们称之为存储类的原始数据类型,这些数据类型比数据类型更通用:INTEGER 存储类包括 6 种不同类型的整数。
| 存储类 | 意义 |
|---|---|
| 零 | NULL 值表示缺少信息或未知 |
| 整数 | 整数和可变大小,如 1、2、3、4 或 8 字节 |
| 真正 | 使用 8 字节浮点数的十进制值的实数 |
| 发短信 | 存储无限长度的字符数据。支持各种字符编码 |
| 斑点 | 二进制大对象,可以存储任何长度的任何类型的数据 |
-
值的数据类型由以下规则采用:
- 如果文本没有括起来的引号和小数点或指数,SQLite 将分配 INTEGER 存储类
- 如果文本用单引号或双引号括起来,SQLite 将分配 TEXT 存储类
- 如果文本没有引号、小数点或指数,SQLite 将分配 REAL 存储类
- 如果文本为不带引号的 NULL,则为其分配 NULL 存储类
- 如果文本的格式为 X'ABCD' 或 x'ábcd' SQLIte 则分配 BLOB 存储类。 •日期和时间可以存储为文本,整数或真实数
当存在不同的存储类时,数据如何排序?
遵循以下规则:
- 空存储类具有最低值...在 NULL 值之间没有顺序
- 下一个更高的存储类是 INTEGER 和 REAL,在数字上比较它们
- 下一个更高的存储类是 TEXT,根据排序规则比较它们
- 最高的存储类是 BLOB,使用 C 函数 memcmp() 来比较 BLOB 值
使用 ORDER BY 时,遵循 2 个步骤:
- 基于存储类对值进行分组:空、整数、实数、文本、BLOB
- 对每个组中的值进行排序
因此,即使引擎在一列中允许不同类型的类型,也不是一个好主意!
清单类型和类型相关性
- 清单类型意味着数据类型是存储在列中的值的属性,而不是存储值的列的属性。任何类型的值都可以存储在列中
- 类型相关性是存储在该列中的数据的推荐类型 - 推荐,不是必需的
SELECT typeof(100), typeof(10.0), typeof('100'), typeof(x'1000'), typeof(NULL);
In sqlite_orm typeof is typeof_.
创建表
sqlite_orm我们使用 make_storage() 函数创建表、索引、唯一约束、检查约束和触发器。我们要持久化的结构的每个数据字段都映射到表中的一列 - 但我们不必添加所有数据字段:结构可能具有不可存储的字段。因此,首先我们定义类型,规范化13它们并创建结构。这些结构可以称为“持久原子”。
struct User {
int id;
std::string name;
std::vector<char> hash; // binary format
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("blob.sqlite",
make_table("users",
make_column("id", &User::id),
make_column("name", &User::name, default_value(“?”)),
make_column("hash", &User::hash)));
storage.sync_schema();
}
这将创建一个名为 blob.sqlite 的数据库和一个名为 users 的包含 3 列的表。sync_schema() 将架构与数据库同步,但并不总是适用于现有表。解决方法是删除表并从 cero 启动架构。向现有表添加唯一性约束通常不起作用...您需要对表进行版本控制以执行一些架构更改。它还定义了列“名称”的默认值。
检查约束
确保列中的值满足表达式定义的指定条件:
struct Contact {
int id = 0;
std::string firstName;
std::string lastName;
std::string email;
std::string phone;
};
struct Product {
int id = 0;
std::string name;
float listPrice = 0;
float discount = 0;
};
auto storage = make_storage(":memory:",
make_table("contacts",
make_column("contact_id", &Contact::id),
make_column("first_name", &Contact::firstName),
make_column("last_name", &Contact::lastName),
make_column("email", &Contact::email),
make_column("phone", &Contact::phone),
check(length(&Contact::phone) >= 10)),
make_table("products",
make_column("product_id", &Product::id, primary_key()),
make_column("product_name", &Product::name),
make_column("list_price", &Product::listPrice),
make_column("discount", &Product::discount, default_value(0)),
check(c(&Product::listPrice) >= &Product::discount and
c(&Product::discount) >= 0 and c(&Product::listPrice) >= 0)));
storage.sync_schema();
这将添加一个检查约束和一个具有默认值的列。
具有特定排序规则的列和具有主键的表
struct User {
int id;
std::string name;
time_t createdAt;
};
struct Foo {
std::string text;
int baz;
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage(
"collate.sqlite",
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name),
make_column("created_at", &User::createdAt)),
make_table("foo", make_column("text", &Foo::text, collate_nocase()), make_column("baz", &Foo::baz)));
storage.sync_schema();
}
这将创建一个不区分大小写的文本列(存在其他排序规则:collate_rtrim 和 collate_binary)。
外键约束
struct Artist {
int artistId;
std::string artistName;
};
struct Track {
int trackId;
std::string trackName;
std::optional<int> trackArtist; // must map to &Artist::artistId
};
int main(int, char** argv) {
cout << "path = " << argv[0] << endl;
using namespace sqlite_orm;
{ // simple case with foreign key to a single column without actions
auto storage = make_storage("foreign_key.sqlite",
make_table("artist",
make_column("artistid", &Artist::artistId, primary_key()),
make_column("artistname", &Artist::artistName)),
make_table("track",
make_column("trackid", &Track::trackId, primary_key()),
make_column("trackname", &Track::trackName),
make_column("trackartist", &Track::trackArtist),
foreign_key(&Track::trackArtist).references(&Artist::artistId)));
auto syncSchemaRes = storage.sync_schema();
for (auto& p : syncSchemaRes) {
cout << p.first << " " << p.second << endl;
}
}
}
这个定义了一个简单的外键。
struct User {
int id;
std::string firstName;
std::string lastName;
};
struct UserVisit {
int userId;
std::string userFirstName;
time_t time;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage(
{},
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("first_name", &User::firstName),
make_column("last_name", &User::lastName),
primary_key(&User::id, &User::firstName)),
make_table("visits",
make_column("user_id", &UserVisit::userId),
make_column("user_first_name", &UserVisit::userFirstName),
make_column("time", &UserVisit::time),
foreign_key(&UserVisit::userId, &UserVisit::userFirstName)
.references(&User::id, &User::firstName)));
storage.sync_schema();
}
这将定义复合外键和相应的复合主键。
自动增量属性
struct DeptMaster {
int deptId = 0;
std::string deptName;
};
struct EmpMaster {
int empId = 0;
std::string firstName;
std::string lastName;
long salary;
decltype(DeptMaster::deptId) deptId;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage("", // empty db name means in memory db
make_table("dept_master",
make_column("dept_id", &DeptMaster::deptId, primary_key(), autoincrement()),
make_column("dept_name", &DeptMaster::deptName)),
make_table("emp_master",
make_column("emp_id", &EmpMaster::empId, autoincrement(), primary_key()),
make_column("first_name", &EmpMaster::firstName),
make_column("last_name", &EmpMaster::lastName),
make_column("salary", &EmpMaster::salary),
make_column("dept_id", &EmpMaster::deptId)));
storage.sync_schema();
}
这将两个主键定义为 autoincrement(),因此,如果您不为主键指定 aa 值,则会按顺序创建一个主键。您还可以使用 replace 显式确定主键。
GENERATED COLUMNS
struct Product {
int id = 0;
std::string name;
int quantity = 0;
float price = 0;
float totalValue = 0;
};
auto storage = make_storage({},
make_table("products",
make_column("id", &Product::id, primary_key()),
make_column("name", &Product::name),
make_column("quantity", &Product::quantity),
make_column("price", &Product::price),
make_column("total_value",&Product::totalValue,
generated_always_as(&Product::price * c(&Product::quantity)))));
storage.sync_schema();
这将定义一个生成的列!
如果需要,可以在内存中创建数据库
通过使用特殊名称“:memory:”或只是一个空名称,指示 SQLITE 在内存中创建数据库。
struct RapArtist {
int id;
std::string name;
};
int main(int, char**) {
auto storage = make_storage(":memory:",
make_table("rap_artists",
make_column("id", &RapArtist::id, primary_key()),
make_column("name", &RapArtist::name)));
cout << "in memory db opened" << endl;
storage.sync_schema();
}
这个存储在内存中(也可以将 dbname 留空以达到相同的效果)。
指数和唯一指数
struct Contract {
std::string firstName;
std::string lastName;
std::string email;
};
using namespace sqlite_orm;
// beware - put `make_index` before `make_table` cause `sync_schema` is called in reverse order
// otherwise you'll receive an exception
auto storage = make_storage(
"index.sqlite",
make_index("idx_contacts_name", &Contract::firstName, &Contract::lastName,
where(length(&Contract::firstName) > 2)),
make_unique_index("idx_contacts_email", indexed_column(&Contract::email).collate("BINARY").desc()),
make_table("contacts",
make_column("first_name", &Contract::firstName),
make_column("last_name", &Contract::lastName),
make_column("email", &Contract::email)));
这允许您创建索引和唯一索引。
日期列的默认值
struct Invoice
{
int id;
int customerId;
std::optional<std::string> invoiceDate;
};
using namespace sqlite_orm;
int main(int, char** argv) {
cout << argv[0] << endl;
auto storage = make_storage("aliases.sqlite",
make_table("Invoices", make_column("id", &Invoice::id, primary_key(), autoincrement()),
make_column("customerId", &Invoice::customerId),
make_column("invoiceDate", &Invoice::invoiceDate, default_value(date("now")))));
这个将发票日期的默认值定义为插入时的当前日期。
持久集合
/**
* This is just a mapped type.
*/
struct KeyValue {
std::string key;
std::string value;
};
auto& getStorage() {
using namespace sqlite_orm;
static auto storage = make_storage("key_value_example.sqlite",
make_table("key_value",
make_column("key", &KeyValue::key, primary_key()),
make_column("value", &KeyValue::value)));
return storage;
}
void setValue(const std::string& key, const std::string& value) {
using namespace sqlite_orm;
KeyValue kv{key, value};
getStorage().replace(kv);
}
std::string getValue(const std::string& key) {
using namespace sqlite_orm;
if(auto kv = getStorage().get_pointer<KeyValue>(key)) {
return kv->value;
} else {
return {};
}
}
实现持久映射。
GETTERS and SETTERS
class Player {
int id = 0;
std::string name;
public:
Player() {}
Player(std::string name_) : name(std::move(name_)) {}
Player(int id_, std::string name_) : id(id_), name(std::move(name_)) {}
std::string getName() const {
return this->name;
}
void setName(std::string name) {
this->name = std::move(name);
}
int getId() const {
return this->id;
}
void setId(int id) {
this->id = id;
}
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("private.sqlite",
make_table(“players",
make_column("id",
&Player::setId, // setter
&Player::getId, // getter
primary_key()),
make_column("name",
&Player::getName, // order between setter and getter doesn't matter.
&Player::setName)));
storage.sync_schema();
}
这个使用getter和setter(注意顺序无关紧要)。
DEFINING THE SHEMA FOR SELF-JOINS
struct Employee {
int employeeId;
std::string lastName;
std::string firstName;
std::string title;
std::unique_ptr<int> reportsTo; // can also be std::optional<int> for nullable columns
std::string birthDate;
std::string hireDate;
std::string address;
std::string city;
std::string state;
std::string country;
std::string postalCode;
std::string phone;
std::string fax;
std::string email;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage("self_join.sqlite",
make_table("employees",
make_column("EmployeeId", &Employee::employeeId, autoincrement(), primary_key()),
make_column("LastName", &Employee::lastName),
make_column("FirstName", &Employee::firstName),
make_column("Title", &Employee::title),
make_column("ReportsTo", &Employee::reportsTo),
make_column("BirthDate", &Employee::birthDate),
make_column("HireDate", &Employee::hireDate),
make_column("Address", &Employee::address),
make_column("City", &Employee::city),
make_column("State", &Employee::state),
make_column("Country", &Employee::country),
make_column("PostalCode", &Employee::postalCode),
make_column("Phone", &Employee::phone),
make_column("Fax", &Employee::fax),
make_column("Email", &Employee::email),
foreign_key(&Employee::reportsTo).references(&Employee::employeeId)));
storage.sync_schema();
}
SUBENTITIES
class Mark {
public:
int value;
int student_id;
};
class Student {
public:
int id;
std::string name;
int roll_number;
std::vector<decltype(Mark::value)> marks;
};
using namespace sqlite_orm;
auto storage = make_storage("subentities.sqlite",
make_table("students",
make_column("id", &Student::id, primary_key()),
make_column("name", &Student::name),
make_column("roll_no", &Student::roll_number)),
make_table("marks",
make_column("mark", &Mark::value),
make_column("student_id", Mark::student_id),
foreign_key(&Mark::student_id).references(&Student::id)));
// inserts or updates student and does the same with marks
int addStudent(const Student& student) {
auto studentId = student.id;
if(storage.count<Student>(where(c(&Student::id) == student.id))) {
storage.update(student);
} else {
studentId = storage.insert(student);
}
// insert all marks within a transaction
storage.transaction([&] {
storage.remove_all<Mark>(where(c(&Mark::student_id) == studentId));
for(auto& mark: student.marks) {
storage.insert(Mark{mark, studentId});
}
return true;
});
return studentId;
}
/**
* To get student from db we have to execute two queries:
* `SELECT * FROM students WHERE id = ?`
* `SELECT mark FROM marks WHERE student_id = ?`
*/
Student getStudent(int studentId) {
auto res = storage.get<Student>(studentId);
res.marks = storage.select(&Mark::value, where(c(&Mark::student_id) == studentId));
return res; // must be moved automatically by compiler
}
This one implements a sub-entity.
列和表级别的唯一性
struct Entry {
int id;
std::string uniqueColumn;
std::unique_ptr<std::string> nullableColumn;
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("unique.sqlite",
make_table("unique_test",
make_column("id", &Entry::id, autoincrement(), primary_key()),
make_column("unique_text", &Entry::uniqueColumn, unique()),
make_column("nullable_text", &Entry::nullableColumn),
unique(&Entry::id, &Entry::uniqueColumn)));
这在列和表级别实现了唯一性。
非空约束
默认情况下,持久结构的每个数据字段都不为 null。如果我们希望在列中允许空值,则相应字段的类型必须是以下类型之一:
- 标准::unique_ptr
- 标准::shared_ptr
- 标准::可选
VACUUM
Why do we need vacuum?
- 删除数据库对象(如表、视图、索引或触发器)会将它们标记为空闲,但数据库大小不会减小。
- 每次在表中插入或删除数据时,索引和表都会变得碎片化
- 插入、更新和删除操作减少了单个页中可以存储的行数 => 增加了保存表所需的页数 => 降低了缓存性能和读/写时间
- Vacuum 对数据库对象进行碎片整理,重新打包忽略可用空间的单个页面 - 它重建数据库并允许更改数据库特定的配置参数,例如页面大小、页面格式和默认编码......只需使用编译指示设置新值并继续真空即可。
storage.vacuum();
触发器 Triggers
什么是触发器?
对关联表发出 INSERT、UPDATE 或 DELETE 语句时自动执行的命名数据库代码。
-
我们为什么需要它们?
- 审计:记录敏感数据(例如工资、电子邮件)中的更改
- 在数据库级别强制实施复杂的业务规则并防止无效事务
语法:
CREATE TRIGGER [IF NOT EXISTS] trigger_name
[BEFORE|AFTER|INSTEAD OF14] [INSERT|UPDATE|DELETE]
ON table_name
[WHEN condition]
BEGIN
statements;
END;
根据操作访问旧列值和新列值
| 行动 | 可用性 |
|---|---|
| 插入 | 新品可用 |
| 更新 | 新旧均可使用 |
| 删除 | 旧可用 |
触发器示例
// CREATE TRIGGER validate_email_before_insert_leads
// BEFORE INSERT ON leads
// BEGIN
// SELECT
// CASE
// WHEN NEW.email NOT LIKE '%_@__%.__%' THEN
// RAISE (ABORT,'Invalid email address')
// END;
// END;
make_trigger("validate_email_before_insert_leads",
before()
.insert()
.on<Lead>()
.begin(select(case_<int>()
.when(not like(new_(&Lead::email), "%_@__%.__%"),
then(raise_abort("Invalid email address")))
.end()))
.end())
// CREATE TRIGGER log_contact_after_update
// AFTER UPDATE ON leads
// WHEN old.phone <> new.phone
// OR old.email <> new.email
// BEGIN
// INSERT INTO lead_logs (
// old_id,
// new_id,
// old_phone,
// new_phone,
// old_email,
// new_email,
// user_action,
// created_at
// )
// VALUES
// (
// old.id,
// new.id,
// old.phone,
// new.phone,
// old.email,
// new.email,
// 'UPDATE',
// DATETIME('NOW')
// ) ;
// END;
make_trigger("log_contact_after_update",
after()
.update()
.on<Lead>()
.when(is_not_equal(old(&Lead::phone), new_(&Lead::phone)) and
is_not_equal(old(&Lead::email), new_(&Lead::email)))
.begin(insert(into<LeadLog>(),
columns(&LeadLog::oldId,
&LeadLog::newId,
&LeadLog::oldPhone,
&LeadLog::newPhone,
&LeadLog::oldEmail,
&LeadLog::newEmail,
&LeadLog::userAction,
&LeadLog::createdAt),
values(std::make_tuple(
old(&Lead::id),
new_(&Lead::id),
old(&Lead::phone),
new_(&Lead::phone),
old(&Lead::email),
new_(&Lead::email),
"UPDATE",
datetime("NOW")))))
.end())
// CREATE TRIGGER validate_fields_before_insert_fondos
// BEFORE INSERT
// ON Fondos
// BEGIN
// SELECT CASE WHEN NEW.abrev = '' THEN RAISE(ABORT, "Fondo abreviacion empty") WHEN LENGTH(NEW.nombre) = 0 // THEN
RAISE(ABORT, "Fondo nombre empty") END;
// END;
make_trigger("validate_fields_before_insert_fondos",
before()
.insert()
.on<Fondo>()
.begin(select(case_<int>()
.when(is_equal(new_(&Fondo::abreviacion),""),
then(raise_abort("Fondo abreviacion empty")))
.when(is_equal(length(new_(&Fondo::nombre)), 0),
then(raise_abort("Fondo nombre empty")))
.end()))
.end())
// CREATE TRIGGER validate_fields_before_update_fondos
// BEFORE UPDATE
// ON Fondos
// BEGIN
// SELECT CASE WHEN NEW.abrev = '' THEN RAISE(ABORT, "Fondo abreviacion empty") WHEN LENGTH(NEW.nombre) = 0 // THEN
RAISE(ABORT, "Fondo nombre empty") END;
// END;
make_trigger("validate_fields_before_update_fondos",
before()
.update()
.on<Fondo>()
.begin(select(case_<int>()
.when(is_equal(new_(&Fondo::abreviacion), ""),
then(raise_abort("Fondo abreviacion empty")))
.when(is_equal(length(new_(&Fondo::nombre)), 0),
then(raise_abort("Fondo nombre empty")))
.end()))
.end())
数据迁移
Sqlite_orm在一定程度上支持自动架构迁移,但有一些注意事项。目前,您可以更改存储架构并调用 storage.sync_schema(true),这将尝试将当前架构应用于数据库。它可以做的事情是有限制的,目前我们不支持数据迁移原语,如add_column(),drop_column()等。但是,sync_schema方法将尝试检测存储架构和数据库架构之间的更改,并尝试在大多数情况下在不丢失数据的情况下进行协调。然而,也有非常明显的例外,我们正在研究它们。首先,并非将列的所有属性或表的属性都与数据库架构进行比较。这目前是 sqlite3 table_xinfo编译指示的限制,而不是sqlite_orm本身的限制。其次,外键检查机制有一个常见的问题来源,这使得对需要删除和重新创建的表进行备份变得非常困难。碰巧的是,当表具有依赖行时,通常无法删除它。我们目前只知道两种解决方案:一种是使用 sqlite 客户端(如 SqliteStudio 或 DB Browser for Sqlite)暂时删除表的所有外键约束(请参阅工具部分)。这将允许备份当前表,因为该过程需要删除表作为其步骤之一。另一种方法存在争议,但这些工具和一些开发人员使用这种方法来简化该过程。它与在进行备份之前禁用FK检查并在备份后立即还原有关。这不需要删除面向手头表的外键约束。有关如何自动执行架构迁移过程的更多详细信息,请随时与作者联系(请参阅文档末尾的详细信息)。如果数据保留和架构演变对您很重要,则需要这些附加信息。列的哪些方面可以与数据库架构相媲美?首先,列是否是表的主键的一部分。其次,列是否有默认值。第三,该列是否可为空(即它是否接受空值)。第四,列是否隐藏(表示列是generated_always_as())。时期。与物理数据库架构相比,根本无法检测到所有其他更改,例如列的默认值是什么,列的生成值是什么,或者列是否唯一或具有检查约束。要使这些属性中的任何一个更改合并到物理数据库中,我们需要删除并重新创建表。引发此行为的最简单且更安全的方法是暂时删除表的主键约束:这将确保使用备份删除和重新创建表,并保留数据。撇开我们如何处理外键约束不谈,无论是通过 sqlite 客户端工具还是在数据库配置级别,数据保存和模式演进的本质是引发手头表的删除和重新创建,并具有备份过程。sync_schema检测到存储架构上的哪些操作,它如何准确响应?下一节将讨论此主题。
sync_schema() 检测到的架构操作
- 向存储架构添加数据库中不存在的列
- 如果列没有默认值,不可为空,也不会生成,则无法保留该表中的数据。试想一下:对于每个现有行,可以在该列中插入什么值?
- 因此,除非您不关心丢失表的数据,否则严格禁止这样做。如果你想添加一个这样的列,你必须首先添加一个无损列(见下文),然后根据需要调整其属性(因此两步过程是不可避免的)
- 如果列具有默认值、可为空值或已生成15,则将有一个高效且有效的 ALTER TABLE ADD COLUMN 命令。不会丢失表的数据,也不需要备份
- sync_schema_simulate(true) 将返回该表的 sync_schema_result::new_columns_added
- 如果列没有默认值,不可为空,也不会生成,则无法保留该表中的数据。试想一下:对于每个现有行,可以在该列中插入什么值?
- 从数据库中存在的存储架构中删除列
- 将发出“更改表删除列”命令,并且不会发生数据丢失
- 删除表的主键约束16
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失
- 在表上添加主键约束
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失
- 向列添加可空性
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失
- 删除列的可为空性
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失,但
- 在删除可为空性之前,请确保此列中每个现有行的值都不同于 null,否则将发生异常并中断更新过程,将其回滚到初始状态
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失,但
- 向列添加或删除默认值
- 这将生成删除并使用备份重新创建,因此不会发生数据丢失
sync_schema() 未检测到的架构操作
- 更改已具有默认值的列的默认值
- 不会被注意到
- 更改已生成的列的生成值
- 不会被注意到
- 向列或表添加或删除检查子句
- 不会被注意到
- 例如,如果通过切换主键约束来引发删除和备份重新创建,则必须确保现有行通过 check 子句(如果添加一个),否则进程将回滚到初始状态
- 向列或表添加或删除唯一子句(多列)
- 不会被注意到
- 例如,如果通过切换主键约束来引发删除和备份重新创建,则在添加唯一子句时必须确保列的值是不同的,否则如果删除唯一性,则不必担心
- 添加或删除外键约束
- 不会被注意到
同步架构时要考虑的方面
方法 storage.sync_schema(true) 尝试将make_storage调用定义的内存上架构(称为存储架构)与数据库架构同步。我们将探索这种方法可以处理什么,它可以处理哪些变化,它不能处理哪些变化,以及当它不足以满足我们的需求时该怎么做17。当我们不关心数据而只想同步模式时,则使用 storage.sync_schema(false)。
- 如果数据库中存在的表未在 make_storage() 的 make_table() 调用中提及,则不会以任何方式更改或删除它们 – 因此,如果需要,您的 C++ 项目能够处理数据库中表的子集
- 将存储中的每个表与其数据库模拟进行比较,以下规则确定结果:
- 如果表不存在,则将创建该表。
- 如果表存在具有多余列的表,则表将删除列以匹配存储架构中定义的列
- 如果表存在较少的列,则表将添加列以匹配存储架构中定义的列
- 如果模式的差异是可检测到的(见上文),那么如果sync_schema(true)被调用,数据将被保留
- 否则,架构之间的差异将保持冲突
- 对于存储和数据库架构之间未检测到的差异,有必要引发表的删除和重新创建;这可以通过以下方法之一完成:
- 更改列的可空性:如果删除可空性,请确保在触发之前列的行中没有空值
- 更改列的默认值(如果是临时的,请记住还原)
- 更改列的主键约束(之后必须恢复它!
- 添加存储类型的生成列(请务必在之后将其删除!
关于使用 sqlite 客户端工具删除 FK 的正确顺序
- 如果我们有一个需要删除并使用备份重新创建的表,要同步其架构,我们必须从针对它的表中删除 FK
- 然后我们继续触发删除并通过运行 sync_schema(true) 使用备份重新创建
- 之后,我们使用 sqlite 客户端工具在所有表中恢复 FK 约束,我们删除了 FK
通过这种方法,我们通过 sqlite 客户端工具处理 FK 约束18
使用 SqliteStudio 进行 FK 删除/恢复
假设我们需要删除/重新创建在表 Emp 中具有依赖行的 Dept 表。在触发删除/重新创建之前,我们需要从 Emp 表中删除 FK 约束,以便在将架构更改应用于 Department 后进行还原。该过程如下所示:
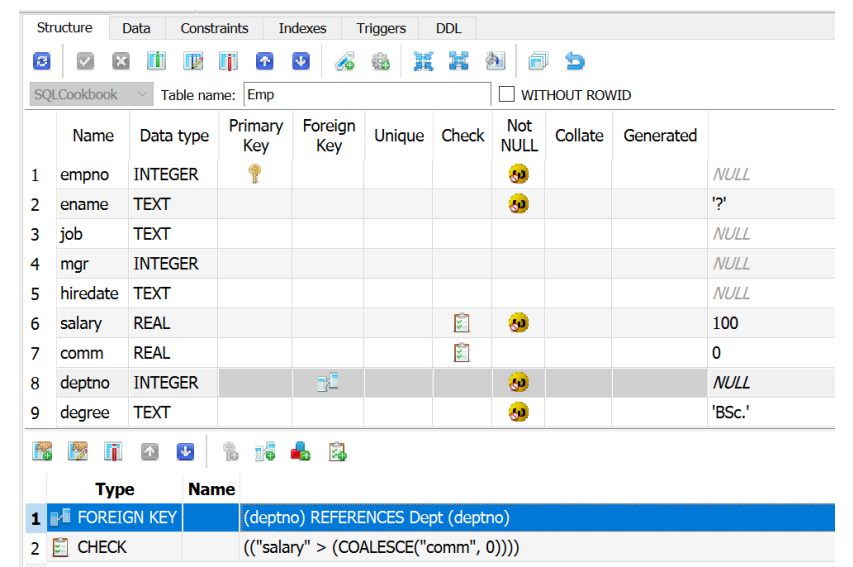
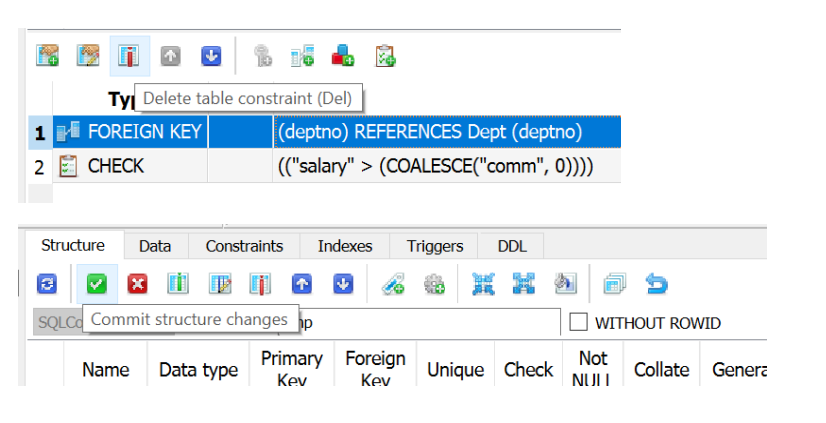
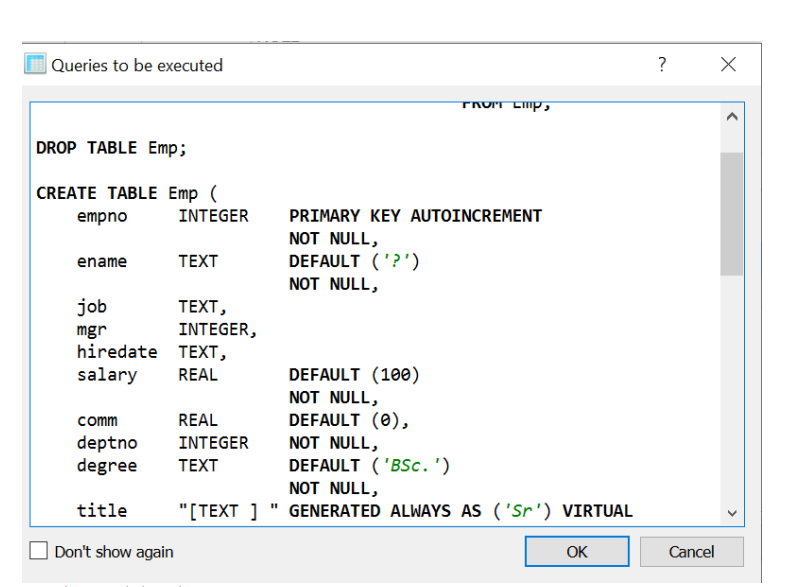
接受建议的架构更改
About correct order of dropping/loading tables1
重新应用模式更改的另一种方法是将每个表的内容加载到 vectors20 中,并使用 storage.drop_table() 删除每个表。然后按保证没有依赖行的顺序删除所有表,并通过调用 storage.sync_schema() 重新创建表。顺序将由以下算法确定:我们必须创建一个由边缘连接的所有表的图,从带有外键的表到该外键引用的表,然后从叶子开始删除。我们将重新创建所有表,并以与删除中使用的表相反的顺序重新加载它们。
例子
考虑一个包含两个表的简单模式,一个用于用户,一个用于作业,假设我们要删除并重新创建它们(或者sync_schema将尝试为我们执行此操作)。我们必须确保在删除引用的表时不存在具有依赖行的表,否则我们将得到异常。
static auto storage = make_storage(dbFilePath,
make_unique_index("name_unique.idx", &User::name ),
make_table("user_table",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name),
make_column("born", &User::born),
make_column("job", &User::job),
make_column("blob", &User::blob),
make_column("age", &User::age ),
check(length(&User::name) > 2),
check(c(&User::born) != 0),
foreign_key(&User::job).references(&Job::id)),
make_table("job",
make_column("id", &Job::id, primary_key(), autoincrement()),
make_column("name", &Job::name, unique()),
make_column("base_salary", &Job::base_salary)));
现在按正确的顺序加载和删除表:
std::vector<User> users = storage.get_all<User>();
storage.drop_table(storage.tablename<User>());
std::vector<Job> jobs = storage.get_all<Job>();
storage.drop_table(storage.tablename<Job>());
现在调用 sync_schema() 将更改传播到数据库:
auto m = storage.sync_schema(false); // we may inspect the return ‘m’ for information of actions performed
并以正确的顺序重新加载表(与删除中使用的顺序相反):
storage.replace_range(jobs.begin(), jobs.end());
storage.replace_range(users.begin(), users.end());
如何在不丢失数据的情况下删除数据
当我们的存储模式和 sync_schema() 函数可检测到的数据库之间存在差异并且它会触发删除和重新创建表时,或者当差异无法检测到时,我们必须执行以下操作以保持模式同步:
- 调用 make_storage()
- 如果更改将添加不可为空且没有默认值且未生成的列,请考虑创建具有这些属性之一的中间列,然后更改属性;不要只在一个步骤中添加这样的列,因为您将丢失所有表数据!
- 按照关于删除/加载表的正确顺序21 中指定的顺序加载当前表和当前表的传递依赖表中的所有数据
- 如果 case 从不可为空的列移动到可为空的列,则决定我们将解释为空值的内容(如果有的话),并修改加载的数据以将其更改为空值,如将不可为空列中的值解释为可为空中所述
- 按上述第 2 点给出的顺序删除表
- 调用 sync_schema(false) – 我们不使用 sync_schema() 的备份功能,因此使用 false 作为参数
- 将所有数据从 std::vector 替换为表中,其顺序与我们删除它们的顺序相反
将不可为空列中的值解释为可为空
如果我们要将可为空的列添加到数据库中不可为空的现有列中,那么我们需要决定是否要将某些值解释为可为空并修改向量的元素。
- 例如:a。对于整数或实数,是否将 0 视为空?
- 对于文本,是否将 “” 视为空?
- 对于 blob,std::vector == 0 的 size() 是否被视为空?
- 如果我们决定将这些值视为空值,那么我们必须按照此模式将可为空的列转换为 std::nullopt,然后再将向量替换到表中。例如,如果列作业的类型是整数或实数,那么我们检查它的值是否为 0,如果是,我们将其替换为 std::nullopt,它在 SQL 中被解释为 NULL:
std::transform(users.begin(), users.end(), users.begin(), [](User& user)
{
if (user.job && user.job.value() == 0) { user.job = std::nullopt; } return user;
});
备份整个数据库
template<typename T>
void backup_db(T& storage, std::string db_name)
{
namespace fs = std::filesystem;
auto path_to_db_name = fs::path(db_name);
auto stem = path_to_db_name.stem().string();
auto backup_stem = stem + "_backup1.sqlite";
auto backup_full_path = path_to_db_name.parent_path().append(backup_stem).string();
storage.backup_to(backup_full_path);
}
在使列唯一之前确保列包含唯一值
如果我们有一个持久结构 User,其列年龄要声明为唯一,我们必须首先检测表中是否有重复项。考虑:
- 将表加载到向量中
- 按年龄对表进行排序
- 使用算法查找是否存在重复值adjacent_find
- 将返回值与 vector 的结束迭代器进行比较:如果它不同,那么我们有一个必须更正的副本!
代码可以是这样的:
std::vector<User> users = storage.get_all<User>();
std::sort(users.begin(), users.end(), [](const User& l, const User& r) { return l.age < r.age; });
auto it = std::adjacent_find(users.begin(),users.end(),[](const User& l, const User& r) { return l.age == r.age; });
if( it!= users.end()) {
// there are duplicates!
User user = *it; // points to duplicate
auto age = user.age; // duplicate age
}
SQLite 工具
SQLite Studio 和 Sqlite3 命令外壳
GUI开源功能齐全的SQLite客户端可从SQLiteStudio下载,运行在Windows,Linux和MacOS X上,使用Qt 5.15.2和SQLite 3.35.4编写C++。
Sqlite3.exe命令外壳和其他命令行实用程序,甚至可以从SQLite下载页面下载源代码。
安装 sqlite_orm 库和 DSL
转到 fnc12/sqlite_orm:❤用于现代C++的 SQLite ORM 光头库 (github.com),然后单击名为 Code 的绿色按钮。复制“HTTPS”选项卡下的 URL。打开命令行22终端并导航到您选择的目标目录。在那里编写以下命令:
- git 克隆https://github.com/fnc12/sqlite_orm.git
- git 结帐开发
- 任何想要使用 DSL 的项目sqlite_orm都需要包含路径包含 %INSTALLATION_DIR%/包含
若要生成用于在 Windows 操作系统中进行单元测试的C++项目,请执行以下操作:
- 从“开始”菜单执行 CMake-GUI
- 使用放置源代码的文件夹并为二进制文件创建一个目录(这里我选择了一个名为 sqlite_orm_binary 的项目外目录)。
- 按配置按钮。你会得到一个关于sqlite3.h和sqlite3.lib位置的错误,如下所示:
C:/Program Files/CMake/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:230 处的 CMake 错误(消息):找不到 SQLite3(缺少:SQLite3_INCLUDE_DIR SQLite3_LIBRARY)
- 按SQLite3_INCLUDE_DIR上的右键,找到找到 sqlite3.h 的路径,例如:

- 然后按SQLite3_LIBRARY上的右键并找到 sqlite3.lib,例如:
- 再次按配置。它应该编译没有错误。
- 按生成,二进制文件将在二进制选择文件夹中创建。
- 现在可以转到该文件夹并打开 Visual Studio 2022 .sln文件,其中包含所有称为:sqlite_orm.sln 的单元测试
- 在VS 2022中打开该文件并编译并运行测试...一切都应该按预期工作。
- 您的库现在可供使用。
在 Windows 中使用 vcpkg 安装 SQLite
Microsoft 提供了一个名为 Microsoft/vcpkg 的开源库管理工具,可在 Microsoft/vcpkg 上找到:C++ Library Manager for Windows、Linux 和 MacOS (github.com),并可按照 microsoft/vcpkg 上的说明进行安装:C++ Library Manager for Windows、Linux 和 MacOS (github.com)。安装后,在命令行运行以下命令:
\> .\vcpkg\vcpkg install sqlite3:x64-windows
当您打开 Visual Studio 2022 时,创建的项目将自动找到 sqlite3.dll 和 sqlite3.lib。
SQLite 导入和导出 CSV
可以在逗号分隔的文本和表格之间导入和导出。这可以使用命令外壳或 GUI SQLiteStudio 程序来完成(请参阅将 CSV 文件导入 SQLite 表 (sqlitetutorial.net) 和将 SQLite 数据库导出到 CSV 文件 (sqlitetutorial.net))。
SQLite 资源
SQLite 资源 (sqlitetutorial.net)
SQLite 教程 - 掌握的简单方法
SQLite Fast SQLite 主页
SQLite 教程 - w3resource
SQLite 练习、练习、解决方案 - w3resource
fnc12/sqlite_orm: ❤SQLite ORM 光头库,仅现代C++ (github.com)
调试提示
Sync_schema返回值
有关 storage.sync_schema() 所做的事情的信息,我们可以捕获它的返回类型,它是一个 std::map,如下所示:
auto m = storage.sync_schema24(true);
std::ostringstream oss;
for (auto& n : m) {
oss << n.first << " " << n.second << "\t";
}
auto s = oss.str();
访问生成的 SQL
对于任何语句,都可以通过以下步骤获取生成的 SQL:
首先让我们看一个选择:
auto expression = select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission,
&Employee::m_job),
order_by(case_<double>()
.when(is_equal(&Employee::m_job, "SalesMan"),
then(&Employee::m_commission))
.else_(&Employee::m_salary).end()).desc());
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
auto rows = storage.execute(statement);
现在让我们看一个插入:
auto expression = insert(into<Employee>(),
columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission, &Employee::m_job),
values(std::make_tuple("Juan", 224000, 200, "Eng")));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
现在更新:
auto expression = update_all(set(c(&Employee::m_salary) = c(&Employee::m_salary) * 1.3),
where(c(&Employee::m_job) == "Clerk"));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
最后删除:
auto expression = remove_all<Employee>(where(c(&Employee::m_empno) == 6));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
For the object version of these calls, we cannot access so readily the corresponding SQL but it is very predictable:
对于对象选择:
auto objects = storage.get_all<Employee>(); // SELECT * FROM EMP
auto employee = storage.get<Employee>(7499); // SELECT * FROM EMP WHERE id = 7499
对于对象插入:
// INSERT INTO EMP ( 'ALL COLUMNS EXCEPT PRIMARY KEY COLUMNS' )
// VALUES ( 'VALUES TAKEN FROM emp OBJECT')
Employee emp{ -1, "JOSE", "ENG", std::nullopt, "17-DEC-1980", 32000, std::nullopt, 10 };
emp.m_empno = storage.insert(emp);
对于对象更新:
// UPDATE Emp
// SET
// column_name = emp.field_name // for all columns except primary key columns
// // ....
// WHERE empno = emp.m_empno;
emp.m_salary *= 1.3;
storage.update(emp);
对于对象删除:
// DELETE FROM Emp WHERE empno = emp.m_empno
storage.remove<Employee>(emp.m_empno);
// DELETE FROM Emp WHERE 'where clause'
storage.remove_all<Employee>(where(c(&Employee::m_salary) < 1000));
// DELETE FROM Emp
storage.remove_all<Employee>();
sqlite_orm的未来
目前sqlite_orm缺少的最重要的功能是对视图和公用表表达式的支持,特别是由 WITH 子句表示的功能(请参阅 WITH 子句 (sqlite.org)) 和最简单的 SQLite 公用表表达式教程 « 费用博客.动态来自的示例(示例为公用表表达式):
select depno, sum(salary) as total_sal, sum(bonus) as total_bonus from
(
select e.empno,
e.ename,
e.salary,
e.deptno,
b.type,
e.salary * case
when b,type = 1 then .1
when b.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus b
where e.empno = b.empno
and e.deptno =20
) y
group by deptno
下面是一个 WITH 子句的示例:
WITH RECURSIVE approvers(x) AS (
SELECT 'Joanie'
UNION ALL
SELECT company.approver
FROM company, approvers
WHERE company.name=approvers.x AND company.approver IS NOT NULL
)
SELECT * FROM approvers;
引用
[CPPTMP,2005]大卫·亚伯拉罕斯,阿列克谢·古尔托沃伊。C++模板元编程。艾迪生·卫斯理,2005
作者联系信息
本指南的作者Juan Dent-Herrera可以通过以下方式联系juandent@mac.com或致电 (506) 8718-1237。请随时与我联系。我非常愿意帮助您解决您可能遇到的任何问题或疑问!


评论区