


SQLITE_ORM
C++ for writing data intensive applications
C++ is a large language with a very expressive and rich syntax. Perhaps its most salient characteristic is its ability to control the level of abstraction enabling application programming to be done in terms of the problem domain’s concepts. An extension to this capability is the ability to define Domain Specific Languages (DSL) like SQL in terms of “ordinary” C++ code. This makes C++ a very compelling language for writing data intensive applications.
A DSL has the following properties:
- It is a language, that defines: [CPPTMP,216]
- An alphabet (set of symbols)
- Well defined rules stating how the alphabet may be used to build well-formed compositions
- A well-defined subset of all well-formed compositions that are assigned specific meanings
- It is domain specific not general-purpose
- Examples include regular expressions, UML, Morse code
- By this restriction, we gain significantly higher level of abstraction and expressiveness because
- Specialized alphabet and notations allow pattern-matching that matches our mental model
- Enabling writing code in terms close to the abstractions of the problem domain is the characteristic property and motivation behind all DSLs
- We use the language’s notation to write down a statement of the problem itself and the language’s semantics take care of generating a solution
- The most successful DSLs are often declarative languages providing us with notations to describe what rather than how * The how can be seen as a consequence of the what
- In a sense, DSL is an enhancement to object-oriented programming in which the development is done in terms of the problem domain conceptual model
- We are just taking an extra step towards enriched notational support
This document refers to a SQL DSL called SQLITE_ORM, which provides direct support for writing SQL in C++. This is indeed a worthy capability and one that allows for the clear concise creation of data intensive applications. This library is not only a SQL DSL but a sort of object relational tool (ORM1 ) in that it provides means to associate data structures in C++ with relational tables in sqlite3.
One can truly raise C++ abstraction level by thinking in a combination of imperative C++ enhanced with compile time metaprogramming and SQL. The synergy is indeed attractive and powerful.
Working level
SQLITE_ORM allows us to interact with the persistent objects in two fundamentally different styles:
- By columns (pure SQL)
- By objects (SQL mapped to structures)
It is this support for dealing with persistency at the object level that explains the ORM suffix of the library name. Basically, each normalized table in the database may be represented in an application as a struct or class in a 1-to-1 relationship. This allows us to work at a high level of abstraction. We refer to these instances as “persistent atoms” to indicate their normalization and their unbreakable nature.
On the other hand, we have access to all the power and expression of SQL by allowing us to define queries for reading or writing in terms of columns just like you would if working in a relational client, but by virtue of this library being a Domain Specific Language (DSL)2 , it allows us to use C++ code to write SQL. This document is dedicated to every user of the library and can be thought of a dictionary of sorts between SQL and SQLITE_ORM.
The object queries deal with collections of instances of the persistent table associated with the object type. The column queries accessing persistent tables, deal at the column level of the corresponding object types.
Mapping types to tables – making types persistent
In order to work with persistent types we need to map them to tables and columns with a call to make_storage(…) like in this example for type User
struct User {
int id = 0;
std::string name;
};
auto storage = make_storage(
{dbFileName},
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name)));
storage.sync_schema(); // synchronizes memory schema (called storage) with database schema
This creates non-nullable columns by default. To make one column nullable, say name, we must declare name to have one of these types:
- std::optional
- std::unique_ptr>
- std::shared_ptr>
Another point to have in mind is that the fields may have any bindable type which includes all fundamental C++ data types, std::string and std::vector. Other types can be used but you must provide some code to make them bindable (an example is std::chrono::sys_days). In particular enumerations can be bound quite easily, for instance.
Simple query
Simple calculation:
// Select 10/5;
auto rows = storage.select(10/5);
This statement produces std::vector<int>.
// Select 10/5, 2*4;
auto rows = storage.select(columns(10/5, 2*4));
This statement produces std::vector<std::tuple<int, int>>
General SELECT Syntax:
SELECT DISTINCT column_list
FROM table_list
JOIN table ON join_condition
WHERE row_filter
ORDER BY column
LIMIT count OFFSET offset
GROUP BY column
HAVING group_filter;
One table select:
// SELECT name, id FROM User;
auto rows = storage.select(columns(&User::name, &User::id));
auto rows = storage.select(columns(&User::name, &User::id), from<User>());
These statements are equivalent and they produce a std::vector>3 . When the from clause is omitted there is an algorithm that detects all types present in a statement and adds all of them to the from clause. This works immediately when only one type is involved but sometimes we need to add joins to the other tables in which case it is best to use the explicit from<>().
// SELECT * FROM User;
auto rows = storage.select(asterisk<User>());// get all columns from User
Produces std::vector<std::tuple<std::string,int>>
auto objects = storage.get_all<User>(); // get all persistent instances of the User type
Produces std::vector<User>
When dealing with large resultsets
We don’t have to load whole result set into memory! We can iterate the collections!
for(auto& employee: storage.iterate<Employee>()) {
cout << storage.dump(employee) << endl;
}
for(auto& hero: storage.iterate<MarvelHero>(where(length(&MarvelHero::name) < 6))) {
cout << "hero = " << storage.dump(hero) << endl;
}
Sorting rows
Order by
General syntax:
// SELECT select_list FROM table ORDER BY column_1 ASC, column_2 DESC;
Simple order by:
// SELECT "User"."first_name", "User"."last_name" FROM 'User' ORDER BY "User"."last_name" COLLATE NOCASE DESC
Assuming the definition of columns as not nullable; otherwise it would be std::vector,int> if we use std::optional to create the name field
auto rows = storage.select(columns(&User::first_name, &User::last_name), order_by(&User::last_name).desc().collate_nocase());
// SELECT "User"."id", "User"."first_name", "User"."last_name" FROM 'User' ORDER BY "User"."last_name" DESC
auto objects = storage.get_all<User>(order_by(&User::last_name).desc());
Compound order by:
auto rows = storage.select(columns(&User::name, &User::age), multi_order_by(
order_by(&User::name).asc(),
order_by(&User::age).desc()));
auto objects = storage.get_all<User>(multi_order_by(
order_by(&User::name).asc(),
order_by(&User::age).desc()));
Dynamic Order by
Sometimes the exact arguments that determine ordering is not known until at runtime, which is why we have this alternative:
auto orderBy = dynamic_order_by(storage);
orderBy.push_back(order_by(&User::firstName).asc());
orderBy.push_back(order_by(&User::id).desc());
auto rows = storage.get_all<User>(orderBy);
Ordering by a function
// SELECT ename, job from EMP order by substring(job, len(job)-1,2)
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_job),
order_by(substr(&Employee::m_job, length(&Employee::m_job) - 1, 2)));
Dealing with NULLs when sorting
// SELECT "Emp"."ename", "Emp"."salary", "Emp"."comm" FROM 'Emp' ORDER BY CASE WHEN "Emp"."comm" IS NULL THEN 0 ELSE
// 1 END DESC
auto rows = storage.select(
columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(case_<int>()
.when(is_null(&Employee::m_commission), then(0))
.else_(1)
.end()).desc());
This can of course be simplified like this below but using case_ is more powerful (e.g. when you have more than 2 values):
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(is_null(&Employee::m_commission)).asc());
Sorting on a data dependent key
auto rows = storage.select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission),
order_by(case_<double>()
.when(is_equal(&Employee::m_job, "SalesMan"), then(&Employee::m_commission))
.else_(&Employee::m_salary)
.end()).desc());
Filtering Data
Select distinct
SELECT DISTINCT select_list FROM table;
// SELECT DISTINT(name) FROM EMP5
auto names = storage.select(distinct(&Employee::name));
result is of type std::vector<std::optional<std::string>>
auto names = storage.select(distinct(columns(&Employee::name)));
result is of type std::vector<std::tuple<std::optional<std::string>>>
Where Clause
SELECT column_list FROM table WHERE search_condition;
Search condition can be formed from these clauses and their composition with and/or:
- WHERE column_1 = 100;
- WHERE column_2 IN (1,2,3);
- WHERE column_3 LIKE 'An%';
- WHERE column_4 BETWEEN 10 AND 20;
- WHERE expression1 Op expression2
- Op can be any comparison operator:
= (== in C++)!=, <> (!= in C++)<<=>=
// SELECT COMPANY.ID, COMPANY.NAME, COMPANY.AGE, DEPARTMENT.DEPT
// FROM COMPANY, DEPARTMENT
// WHERE COMPANY.ID = DEPARTMENT.EMP_ID;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(is_equal(&Employee::id, &Department::empId)));
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age,&Department::dept),
where(c(&Employee::id) == &Department::empId));
composite where clause: clause1 [and|or] clause2 … and can also be && , or can also be ||.
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId) and c(&Employee::age) < 20);
auto objects = storage.get_all<User>(where(lesser_or_equal(&User::id, 2)
and (like(&User::name, "T%") or glob(&User::name, "*S")))
the where clause can be also be used in UPDATE and DELETE statements.
Limit
Constrain the number of rows returned (limit) by a query optionally indicating how many rows to skip (offset).
// SELECT column_list FROM table LIMIT row_count;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(4));
auto objects = storage.get_all<Employee>(limit(4));
// SELECT column_list FROM table LIMIT row_count OFFSET offset;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(4, offset(3)));
auto objects = storage.get_all<Employee>(limit(4, offset(3)));
// SELECT column_list FROM table LIMIT offset, row_count;
auto rows = storage.select(columns(&Employee::id, &Employee::name, &Employee::age, &Department::dept),
where(c(&Employee::id) == &Department::empId),
limit(3, 4));
auto objects = storage.get_all<Employee>(limit(3, 4));
Using limit with order by:
// get the 2 employees with the second and third higher salary
auto rows = storage.select(columns(&Employee::name, &Employee::salary), order_by(&Employee::salary).desc(),
limit(2, offset(1)));
auto objects = storage.get_all<Employee>(order_by(&Employee::salary).desc(), limit(2, offset(1)));
Between Operator
Logical operator that tests whether a value is inside a range of values including the boundaries.
NOTE: BETWEEN can be used in the WHERE clause of the SELECT, DELETE, UPDATE and REPLACE statements.
// Syntax:
// test_expression BETWEEN low_expression AND high_expression
// SELECT DEPARTMENT_ID FROM departments
// WHERE manager_id
// BETWEEN 100 AND 200
auto rows = storage.select(&Department::id, where(between(&Department::managerId, 100, 200)));
// SELECT DEPARTMENT_ID FROM departments
// WHERE DEPARTMENT_NAME
// BETWEEN “D” AND “F”
auto rows = storage.select(&Department::id, where(between(&Department::dept, "D", "F")));
auto objects = storage.get_all<Department>(where(between(&Department::dept, "D", "F")));
In
Whether a value matches any value in a list or subquery, syntax being:
expression [NOT] IN (value_list|subquery);
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE location_id=1700);
auto rows = storage.select(columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(in(&Employee::departmentId,
select(&Department::id, where(c(&Department::locationId) == 1700)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(in(&Employee::departmentId, ids)));
auto objects = storage.get_all<Employee>(where(in(&Employee::departmentId, {10,20,30} )));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id NOT IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(not_in(&Employee::departmentId, ids)));
auto objects = storage.get_all<Employee>(where(not_in(&Employee::departmentId, { 10,20,30 })));
// SELECT "Emp"."empno", "Emp"."ename", "Emp"."job", "Emp"."salary", "Emp"."deptno" FROM 'Emp' WHERE
// (("Emp"."ename", "Emp"."job", "Emp"."salary") IN (
// SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp'
// INTERSECT
// SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp' WHERE (("Emp"."job" = “Clerk”))))
auto rows = storage.select(columns
(&Employee::m_empno, &Employee::m_ename, &Employee::m_job, &Employee::m_salary, &Employee::m_deptno),
where(c(std::make_tuple( &Employee::m_ename, &Employee::m_job, &Employee::m_salary))
.in(intersect(
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary)),
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
where(c(&Employee::m_job) == "Clerk")
)))));
which of course can be simplified to:
// SELECT "Emp"."empno", "Emp"."ename", "Emp"."job", "Emp"."salary", "Emp"."deptno" FROM 'Emp'
// WHERE(("Emp"."ename", "Emp"."job", "Emp"."salary")
// IN(SELECT "Emp"."ename", "Emp"."job", "Emp"."salary" FROM 'Emp' WHERE(("Emp"."job" = “Clerk”))))
auto rows = storage.select(columns(
&Employee::m_empno, &Employee::m_ename, &Employee::m_job, &Employee::m_salary, &Employee::m_deptno),
where(
in(std::make_tuple(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
select(columns(&Employee::m_ename, &Employee::m_job, &Employee::m_salary),
where(c(&Employee::m_job) == "Clerk")))));
Like
Matches a pattern using 2 wildcards: % and _.
% matches 0 or more characters while _ matches any character. For characters in the ASCII range, the comparison is case insensitive; otherwise it is case sensitive.
SELECT column_list FROM table_name WHERE column_1 LIKE pattern;
auto whereCondition = where(like(&User::name, "S%"));
auto users = storage.get_all<User>(whereCondition);
auto rows = storage.select(&User::id, whereCondition);
auto rows = storage.select(like("ototo", "ot_to"));
auto rows = storage.select(like(&User::name, "%S%a"));
auto rows = storage.select(like(&User::name, "^%a").escape("^"));
Glob
Similar to the like operator but using UNIX wildcards like so:
- The asterisk () matches any number of characters (pattern Man matches strings that start with Man)
- The question mark (?) matches exactly one character (pattern Man? matches strings that start with Man followed by any character)
- The list wildcard [] matches one character from the list inside the brackets. For instance [abc] matches either an a, a b or a c.
- The list wildcard can use ranges as in [a-zA-Z0-9]
- By using ^, we can match any character except those in the list ([^0-9] matches any non-numeric character).
auto rows = storage.select(columns(&Employee::lastName), where(glob(&Employee::lastName, "[^A-J]*")));
auto employees = storage.get_all<Employee>(where(glob(&Employee::lastName, "[^A-J]*")));
IS NULL
// SELECT
// artists.ArtistId,
// albumId
// FROM
// artists
// LEFT JOIN albums ON albums.artistid = artists.artistid
// WHERE
// albumid IS NULL;
auto rows = storage.select(columns(&Artist::artistId, &Album::albumId),
left_join<Album>(on(c(&Album::artistId) == &Artist::artistId)),
where(is_null(&Album::albumId)));
Dealing with NULL values in columns
// Transforming null values into real values
// SELECT COALESCE(comm,0), comm FROM EMP
auto rows = storage.select(columns(coalesce<double>(&Employee::m_commission, 0), &Employee::m_commission));
Joining tables
Table expressions are divided into join and nonjoin table expressions:
Table-expressions ::= join-table-expression | nonjoin-table-expression Join-table-expression := table-reference CROSS JOIN table-reference | table-reference [NATURAL] [join-type] JOIN table-reference [ON conditional-expression] | USING (column-commalist) ] | (join-table-expression)
SQLite join
In SQLite to query data from more than one table you can use INNER JOIN, LEFT JOIN or CROSS JOIN6 . Each clause determines how rows from one table are “linked” to rows in another table. There is no explicit support for RIGHT JOIN or FULL OUTER JOIN. The expression OUTER is optional and does not alter the definition of the JOIN.
Cross join
Cross join is more accurately called the extended Cartesian product. If A and B are the tables from evaluation of the 2 table references then A CROSS JOIN B evaluates to a table consisting of all possible rows R such that R is the concatenation of a row from A and a row from B. In fact, the A CROSS JOIN B join expression is semantically equivalent to the following select-expression:
( SELECT A., B. FROM A,B )
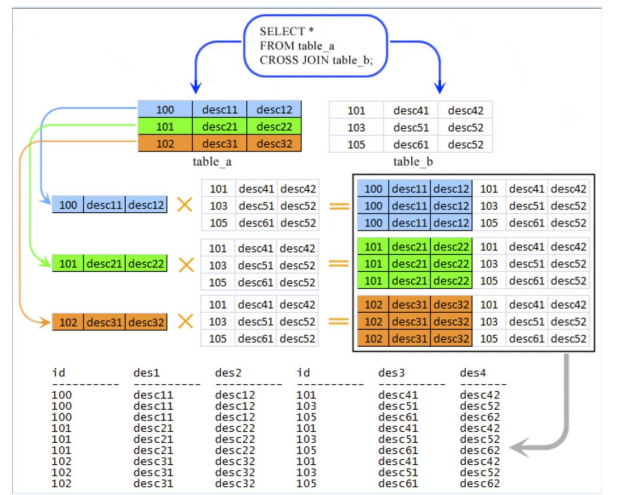
(taken from SQLite CROSS JOIN - w3resource)
Other joins
Table-reference [NATURAL] [ join-type] JOIN table-reference [ ON conditional-expression | using(column-commalist) ]
Join type can be any of
- INNER7
- LEFT [OUTER]
- RIGHT [OUTER]
- FULL [OUTER]
- UNION8
With the following restrictions:
- NATURAL and UNION cannot both be specified
- If either NATURAL or UNION is specified, neither an ON clause nor a USING clause can be specified
- If neither NATURAL nor UNION is specified, then either an ON clause or a USING clause must be specified
- If join-type is omitted, INNER is assumed by default
It is important to realize that OUTER in LEFT, RIGHT and FULL has no effect on the overall semantics of the expression and is thus completely unnecessary. LEFT, RIGHT, FULL and UNION all have to do with NULLs so let’s examine the other ones first:
- Table-reference JOIN table-reference ON conditional-expression
- Table-reference JOIN table-reference USING ( column-commalist )
- Table-reference NATURAL JOIN table-reference
Case 1 is equivalent to the following select-expression where cond is the conditional-expression: (SELECT A., B. FROM A,B WHERE cond)
In case 2, let the commalist of columns in the USING clause be unqualified C1, C2, .., Cn, then it is equivalent to a case 1 with the following ON clause: ON A.C1 = B.C1 AND A.C2 = B.C2 And … A.Cn = B.Cn.
Finally case 3 is equivalent to case 2 where the USING clause contains all the columns that have the same names in A and B.
Joins having to do with NULLs (i.e. OUTER JOINS)
In the INNER joins, when we try to construct the ordinary join of 2 tables A and B, then any row that matches no row in the other table (under the relevant join condition) does not participate in the result. In an outer join such a row participates in the result: it appears exactly once, and the column positions that would have been filled with values from the other table, if such a mapping row had in fact existed, are filled with nulls instead. Therefore the outer join preserves nonmatching rows in the result whereas the inner join excludes them.
A LEFT OUTER JOIN of A and B, preserves rows from A with no matching rows from B. A RIGHT OUTER JOIN of A and B, preserves rows from B with no matching rows from A. A FULL OUTER JOIN preserves both. Lets analyze the particular cases for LEFT OUTER JOIN being that the other cases are similar: We have three options in which to write our LEFT JOIN:
- Table-reference LEFT JOIN table-reference ON conditional-expression
- Table-reference LEFT JOIN table-reference USING (column-commalist)
- Table-reference NATURAL LEFT JOIN table-reference Case 1 can be represented as the following select statement:
SELECT A., B. FROM A,B WHERE condition UNION ALL SELECT A.*, NULL, NULL, …,NULL FROM A WHERE A.pkey NOT IN ( SELECT A.pkey FROM A,B WHERE condition)
Which means the UNION ALL of (a) the corresponding inner join and (b) the collection of rows excluded from the inner join, where there are as many NULL columns as there are columns in B.
For case 2, let the commalist of columns in the USING clause be C1, C2,…, Cn, all Ci unqualified and identifying a common column of A and B. Then the case becomes identical to a case 1 in which the condition has the form: ON (A.C1 = B.C1 AND A.C2 = B.A2, …, A.Cn = B.Cn)
For case 3, the commalist of colums to be used for case 2 is the collection of all common columns from A and B.
Example for Left Join:

// SELECT
// artists.ArtistId,
// albumId
// FROM
// artists
// LEFT JOIN albums ON albums.artistid = artists.artistid
// ORDER BY
// albumid;
auto rows = storage.select(columns(&Artist::artistId, &Album::albumId),
left_join<Album>(on(c(&Album::artistId) == &Artist::artistId)),
order_by(&Album::albumId));
Example for Inner Join
// SELECT
// trackid,
// name,
// title
// FROM
// tracks
// INNER JOIN albums ON albums.albumid = tracks.albumid;
auto innerJoinRows0 = storage.select(columns(&Track::trackId, &Track::name, &Album::title),
inner_join<Album>(on(
c(&Track::albumId) == &Album::albumId)));
In this example, each row from tracks table is matched with a row from albums table according to the on clause. When this clause is true, then columns from the corresponding tables are displayed as an “extended row” – we are actually creating an anonymous type with attributes from the joined tables. The relationship between these tables is N tracks per 1 album. All N tracks with the same albumId are joined with the 1 album with matching columns as per the on clause.
Example for Natural Join
// SELECT doctor_id,doctor_name,degree,patient_name,vdate
// FROM doctors
// NATURAL JOIN visits
// WHERE doctors.degree="MD";
auto rows = storage.select(
columns(&Doctor::doctor_id, &Doctor::doctor_name, &Doctor::degree, &Visit::patient_name, &Visit::vdate),
natural_join<Visit>(),
where(c(&Doctor::degree) == "MD"));
// SELECT doctor_id,doctor_name,degree,spl_descrip,patient_name,vdate
// FROM doctors
// NATURAL JOIN speciality
// NATURAL JOIN visits
// WHERE doctors.degree='MD';
auto rows = storage.select(columns(&Doctor::doctor_id,
&Doctor::doctor_name,
&Doctor::degree,
&Speciality::spl_descrip,
&Visit::patient_name,
&Visit::vdate),
natural_join<Speciality>(),
natural_join<Visit>(),
where(c(&Doctor::degree) == "MD"));
Self join
// SELECT m.FirstName || ' ' || m.LastName,
// employees.FirstName || ' ' || employees.LastName
// FROM employees
// INNER JOIN employees m
// ON m.ReportsTo = employees.EmployeeId
using als = alias_m<Employee>;
auto firstNames = storage.select(
columns(c(alias_column<als>(&Employee::firstName)) || " " || c(alias_column<als>(&Employee::lastName)),
c(&Employee::firstName) || " " || c(&Employee::lastName)),
inner_join<als>(on(alias_column<als>(&Employee::reportsTo) == c(&Employee::employeeId))));
Full outer join
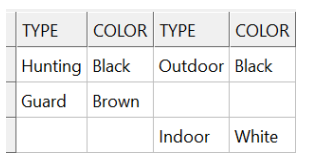
While SQLite does not support FULL OUTER JOIN, it is very easy to simulate it. Take these 2 classes/tables as an example, insert some data and do the “full outer join”:
struct Dog
{
std::optional<std::string> type;
std::optional<std::string> color;
};
struct Cat
{
std::optional<std::string> type;
std::optional<std::string> color;
};
using namespace sqlite_orm;
auto storage = make_storage(
{ "full_outer.sqlite" },
make_table("Dogs", make_column("type", &Dog::type), make_column("color", &Dog::color)),
make_table("Cats", make_column("type", &Cat::type), make_column("color", &Cat::color)));
storage.sync_schema();
storage.remove_all<Dog>();
storage.remove_all<Cat>();
storage.insert(into<Dog>(), columns(&Dog::type, &Dog::color), values(
std::make_tuple("Hunting", "Black"), std::make_tuple("Guard", "Brown")));
storage.insert(into<Cat>(), columns(&Cat::type, &Cat::color), values(
std::make_tuple("Indoor", "White"), std::make_tuple("Outdoor", "Black")));
// FULL OUTER JOIN simulation:
// SELECT d.type,
// d.color,
// c.type,
// c.color
// FROM dogs d
// LEFT JOIN cats c USING(color)
// UNION ALL
// SELECT d.type,
// d.color,
// c.type,
// c.color
// FROM cats c
// LEFT JOIN dogs d USING(color)
// WHERE d.color IS NULL;
auto rows = storage.select(
union_all(select(columns(&Dog::type, &Dog::color, &Cat::type, &Cat::color),
left_join<Cat>(using_(&Cat::color))),
select(columns(&Dog::type, &Dog::color, &Cat::type, &Cat::color), from<Cat>(),
left_join<Dog>(using_(&Dog::color)), where(is_null(&Dog::color)))));
Grouping data
The group by clause is an optional clause of the select statement and enables us to take a selected group of rows into summary rows by values of one or more columns. It returns one row for each group and it is possible to apply an aggregate function such as MIN,MAX,SUM,COUNT or AVG – or one that you program yourself in sqlite_orm9 !
The syntax is:
SELECT column_1, aggregate_function(column_2) FROM table GROUP BY column_1, column_2;
Group by
// If you want to know the total amount of salary on each customer, then GROUP BY query would be as follows:
// SELECT NAME, SUM(SALARY)
// FROM COMPANY
// GROUP BY NAME;
auto salaryName = storage.select(columns(&Employee::name, sum(&Employee::salary)), group_by(&Employee::name));
Group by date example:
// SELECT (STRFTIME(“%Y”, "Invoices"."invoiceDate")) AS InvoiceYear,
// (COUNT("Invoices"."id")) AS InvoiceCount FROM 'Invoices' GROUP BY InvoiceYear
// ORDER BY InvoiceYear DESC
struct InvoiceYearAlias : alias_tag {
static const std::string& get() {
static const std::string res = "INVOICE_YEAR";
return res;
}
};
auto statement = storage.select(columns(as<InvoiceYearAlias>(strftime("%Y", &Invoice::invoiceDate)),
as<InvoiceCountAlias>(count(&Invoice::id))), group_by(get<InvoiceYearAlias>()),
order_by(get<InvoiceYearAlias>()).desc());
Having
While the where clause restricts the rows selected, the having clause selects data at the group level. For instance:
// SELECT NAME, SUM(SALARY)
// FROM COMPANY
// WHERE NAME is like "%l%"
// GROUP BY NAME
// HAVING SUM(SALARY) > 10000
auto namesWithHigherSalaries = storage.select(columns(&Employee::name, sum(&Employee::salary)),
where(like(&Employee::name, "%l%")),
group_by(&Employee::name).having(sum(&Employee::salary) > 10000));
Set operators
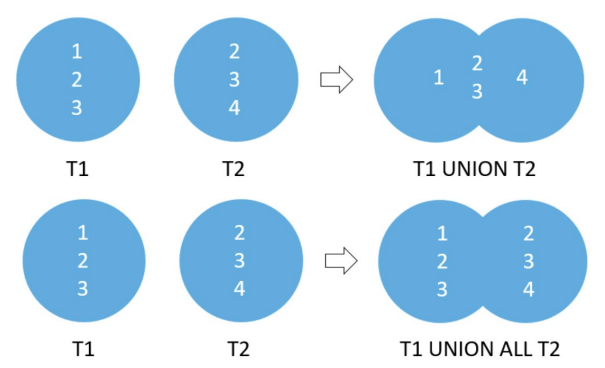
Union
The difference between UNION and JOIN Is that the JOIN clause combines columns from multiple related tables while UNION combines rows from multiple similar tables. The UNION operator removes duplicate rows, whereas the UNION ALL operator does not. The rules for using UNION are as follows:
- Number of columns in all queries must be the same
- The corresponding columns must have compatible data types
- The column names of the first query determine the column names of the combined result set
- The group by and having clauses are applied to each individual query, not the final result set
- The order by apply to the combined result set, not within the individual result set
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID;
auto rows = storage.select(
union_(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId))))));
Union all:
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION ALL
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
auto rows = storage.select(
union_all(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))))));
Union ALL with order by:
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// INNER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// UNION ALL
// SELECT EMP_ID, NAME, DEPT
// FROM COMPANY
// LEFT OUTER JOIN DEPARTMENT
// ON COMPANY.ID = DEPARTMENT.EMP_ID
// ORDER BY NAME
auto rows = storage.select(
union_all(select(columns(&Department::employeeId, &Employee::name, &Department::dept),
inner_join<Department>(on(is_equal(&Employee::id, &Department::employeeId)))),
select(columns(&Department::employeeId, &Employee::name, &Department::dept),
left_outer_join<Department>(on(is_equal(&Employee::id, &Department::employeeId))),
order_by(&Employee::name))));
Stacking one resultset on top of another
// SELECT "Dept"."deptname" AS ENAME_AND_DNAME, "Dept"."deptno" FROM 'Dept'
// UNION ALL
// SELECT (QUOTE("------------------")), NULL
// UNION ALL
// SELECT "Emp"."ename" AS ENAME_AND_DNAME, "Emp"."deptno" FROM 'Emp'
auto rows = storage.select(
union_all(
select(columns(as<NamesAlias>(&Department::m_deptname), as_optional(&Department::m_deptno))),
select(union_all(
select(columns(quote("--------------------"), std::optional<int>())),
select(columns(as<NamesAlias>(&Employee::m_ename),
as_optional(&Employee::m_deptno))))))));
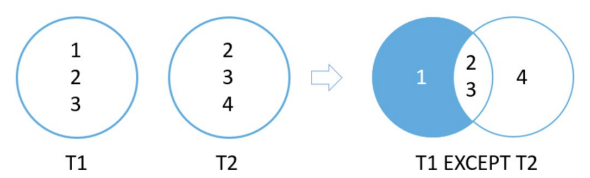
Except
Compares the result sets of 2 queries and retains rows that are present only in the first result set. These are the rules:
- Number of columns in each query must be the same
- The order of the columns and their types must be comparable
Find all the dept_id in dept_master but not in emp_master:
// SELECT dept_id
// FROM dept_master
// EXCEPT
// SELECT dept_id
// FROM emp_master
auto rows = storage.select(except(select(&DeptMaster::deptId), select(&EmpMaster::deptId)));
Find all artists ids of artists who do not have any album in the albums table:
// SELECT ArtistId FROM artists EXCEPT SELECT ArtistId FROM albums;
auto rows = storage.select(except(select(&Artist::m_id), select(&Album::m_artist_id)));
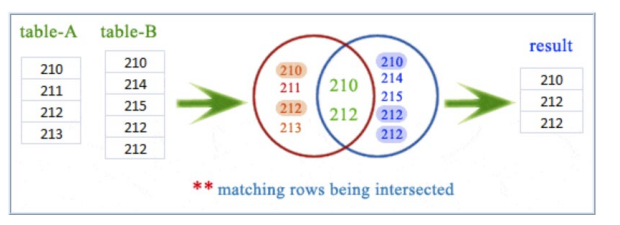
Intersect
Compares the result sets of 2 queries and returns distinct rows that are output by both queries. Syntax:
SELECT select_list1 FROM table1 INTERSECT SELECT select_list2 FROM table2
These are the rules:
- Number of columns in each query must be the same
- The order of the columns and their types must be comparable
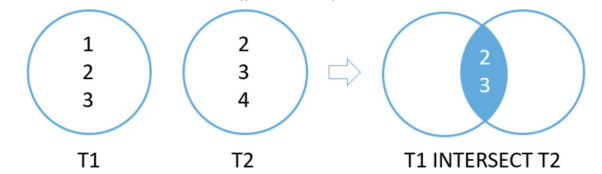
// SELECT dept_id
// FROM dept_master
// INTERSECT
// SELECT dept_id
// FROM emp_master
auto rows = storage.select(intersect(select(&DeptMaster::deptId), select(&EmpMaster::deptId)));
To find the customers who have invoices:
SELECT CustomerId FROM customers INTERSECT SELECT CustomerId FROM invoices ORDER BY CustomerId;
Subquery
Subquery
A subquery is a nested SELECT within another statement such as:
SELECT column_1 FROM table_1 WHERE column_1 = ( SELECT column_1 FROM table_2 );
// SELECT first_name, last_name, salary
// FROM employees
// WHERE salary >(
// SELECT salary
// FROM employees
// WHERE first_name='Alexander');
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::salary),
where(greater_than(&Employee::salary,
select(&Employee::salary,
where(is_equal(&Employee::firstName, "Alexander"))))));
// SELECT employee_id,first_name,last_name,salary
// FROM employees
// WHERE salary > (SELECT AVG(SALARY) FROM employees);
auto rows = storage.select(columns(
&Employee::id, &Employee::firstName, &Employee::lastName, &Employee::salary),
where(greater_than(&Employee::salary,
select(avg(&Employee::salary)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE location_id=1700);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(in(
&Employee::departmentId,
select(&Department::id, where(c(&Department::locationId) == 1700)))));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id IN (10,20,30)
std::vector<int> ids{ 10,20,30 };
auto rows = storage.select(columns(&Employee::firstName, &Employee::departmentId),
where(in(&Employee::departmentId, ids)));
// SELECT * FROM employees
// WHERE department_id IN (10,20,30)
auto objects = storage.get_all<Employee>(where(in(&Employee::departmentId, {10,20,30} )));
// SELECT first_name, last_name, department_id
// FROM employees
// WHERE department_id NOT IN
// (SELECT DEPARTMENT_ID FROM departments
// WHERE manager_id
// BETWEEN 100 AND 200);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::departmentId),
where(not_in(&Employee::departmentId,
select(&Department::id, where(between(&Department::managerId, 100, 200))))));
// SELECT 'e'."LAST_NAME", 'e'."SALARY", 'e'."DEPARTMENT_ID" FROM 'employees' 'e'
// WHERE (('e'."SALARY" > (SELECT (AVG("employees"."SALARY")) FROM 'employees',
// 'employees' e WHERE (("employees"."DEPARTMENT_ID" = 'e'."DEPARTMENT_ID")))))
using als = alias_e<Employee>;
auto rows = storage.select(
columns(alias_column<als>(&Employee::lastName),
alias_column<als>(&Employee::salary),
alias_column<als>(&Employee::departmentId)),
from<als>(),
where(greater_than(
alias_column<als>(&Employee::salary),
select(avg(&Employee::salary),
where(is_equal(&Employee::departmentId, alias_column<als>(&Employee::departmentId)))))));
// SELECT first_name, last_name, employee_id, job_id
// FROM employees
// WHERE 1 <=
// (SELECT COUNT(*) FROM Job_history
// WHERE employee_id = employees.employee_id);
auto rows = storage.select(
columns(&Employee::firstName, &Employee::lastName, &Employee::id, &Employee::jobId), from<Employee>(),
where(lesser_or_equal(
1,
select(count<JobHistory>(), where(is_equal(&Employee::id, &JobHistory::employeeId))))));
SELECT albumid, title, (SELECT count(trackid) FROM tracks WHERE tracks.AlbumId = albums.AlbumId) tracks_count FROM albums ORDER BY tracks_count DESC;
Exists
Logical operator that checks whether subquery returns any rows. The subquery is a select statement that returns 0 or more rows. Syntax:
EXISTS (subquery)
// SELECT agent_code,agent_name,working_area,commission
// FROM agents
// WHERE exists
// (SELECT *
// FROM customer
// WHERE grade=3 AND agents.agent_code=customer.agent_code)
// ORDER BY commission;
auto rows = storage.select(columns(&Agent::code, &Agent::name, &Agent::workingArea, &Agent::comission),
from<Agent>(),
where(exists(select(asterisk<Customer>(), from<Customer>(),
where(is_equal(&Customer::grade, 3)
and is_equal(&Agent::code, &Customer::agentCode))))),
order_by(&Agent::comission));
// SELECT cust_code, cust_name, cust_city, grade
// FROM customer
// WHERE grade=2 AND EXISTS
// (SELECT COUNT(*)
// FROM customer
// WHERE grade=2
// GROUP BY grade
// HAVING COUNT(*)>2);
auto rows = storage.select(columns(&Customer::code, &Customer::name, &Customer::city, &Customer::grade),
where(is_equal(&Customer::grade, 2)
and exists(select(count<Customer>(), where(is_equal(&Customer::grade, 2)),
group_by(&Customer::grade),
having(greater_than(count(), 2))))));
// SELECT "orders"."AGENT_CODE", "orders"."ORD_NUM", "orders"."ORD_AMOUNT", "orders"."CUST_CODE", 'c'."PAYMENT_AMT"
// FROM 'orders' INNER JOIN 'customer' 'c' ON('c'."AGENT_CODE" = "orders"."AGENT_CODE")
// WHERE(NOT(EXISTS
// (
// SELECT 'd'."AGENT_CODE" FROM 'customer' 'd' WHERE((('c'."PAYMENT_AMT" = 7000) AND('d'."AGENT_CODE" =
// 'c'."AGENT_CODE")))))
// )
// ORDER BY 'c'."PAYMENT_AMT"
using als = alias_c<Customer>;
using als_2 = alias_d<Customer>;
double amount = 2000;
auto where_clause = select(alias_column<als_2>(&Customer::agentCode), from<als_2>(),
where(is_equal(alias_column<als>(&Customer::paymentAmt), std::ref(amount)) and
(alias_column<als_2>(&Customer::agentCode) == c(alias_column<als>(&Customer::agentCode)))));
amount = 7000;
auto rows = storage.select(columns(
&Order::agentCode, &Order::num, &Order::amount,&Order::custCode,alias_column<als>(&Customer::paymentAmt)),
from<Order>(),
inner_join<als>(on(alias_column<als>(&Customer::agentCode) == c(&Order::agentCode))),
where(not exists(where_clause)), order_by(alias_column<als>(&Customer::paymentAmt)));
More querying techniques
Case
We can add conditional logic to a query (an if else or switch statement in C++) by using the CASE expression. There are two syntaxes available and either can have column aliases (see below).
CASE case_expression
WHEN case_expression = when_expression_1 THEN result_1
WHEN case_expression = when_expression_2 THEN result_2
...
[ ELSE result_else ]
END
// SELECT CASE "users"."country" WHEN “USA” THEN “Domestic” ELSE “Foreign” END
// FROM 'users' ORDER BY "users"."last_name" , "users"."first_name"
auto rows = storage.select(columns(
case_<std::string>(&User::country)
.when("USA", then("Domestic"))
.else_("Foreign").end()),
multi_order_by(order_by(&User::lastName), order_by(&User::firstName)));
CASE
WHEN when_expression_1 THEN result_1
WHEN when_expression_2 THEN result_2
...
[ ELSE result_else ]
END
// SELECT ID, NAME, MARKS,
// CASE
// WHEN MARKS >=80 THEN 'A+'
// WHEN MARKS >=70 THEN 'A'
// WHEN MARKS >=60 THEN 'B'
// WHEN MARKS >=50 THEN 'C'
// ELSE 'Sorry!! Failed'
// END
// FROM STUDENT;
auto rows = storage.select(columns(&Student::id,
&Student::name,
&Student::marks,
case_<std::string>()
.when(greater_or_equal(&Student::marks, 80), then("A+"))
.when(greater_or_equal(&Student::marks, 70), then("A"))
.when(greater_or_equal(&Student::marks, 60), then("B"))
.when(greater_or_equal(&Student::marks, 50), then("C"))
.else_("Sorry!! Failed")
.end()));
Aliases for columns and tables
For tables:
// SELECT C.ID, C.NAME, C.AGE, D.DEPT
// FROM COMPANY AS C, DEPARTMENT AS D
// WHERE C.ID = D.EMP_ID;
using als_c = alias_c<Employee>;
using als_d = alias_d<Department>;
auto rowsWithTableAliases = storage.select(columns(
alias_column<als_c>(&Employee::id),
alias_column<als_c>(&Employee::name),
alias_column<als_c>(&Employee::age),
alias_column<als_d>(&Department::dept)),
where(is_equal(alias_column<als_c>(&Employee::id), alias_column<als_d>(&Department::empId))));
For columns:
struct EmployeeIdAlias : alias_tag {
static const std::string& get() {
static const std::string res = "COMPANY_ID";
return res;
}
};
struct CompanyNameAlias : alias_tag {
static const std::string& get() {
static const std::string res = "COMPANY_NAME";
return res;
}
};
// SELECT COMPANY.ID as COMPANY_ID, COMPANY.NAME AS COMPANY_NAME, COMPANY.AGE, DEPARTMENT.DEPT
// FROM COMPANY, DEPARTMENT
// WHERE COMPANY_ID = DEPARTMENT.EMP_ID;
auto rowsWithColumnAliases = storage.select(columns(
as<EmployeeIdAlias>(&Employee::id),
as<CompanyNameAlias>(&Employee::name),
&Employee::age,
&Department::dept),
where(is_equal(get<EmployeeIdAlias>(), &Department::empId)));
For columns and tables:
// SELECT C.ID AS COMPANY_ID, C.NAME AS COMPANY_NAME, C.AGE, D.DEPT
// FROM COMPANY AS C, DEPARTMENT AS D
// WHERE C.ID = D.EMP_ID;
auto rowsWithBothTableAndColumnAliases = storage.select(columns(
as<EmployeeIdAlias>(alias_column<als_c>(&Employee::id)),
as<CompanyNameAlias>(alias_column<als_c>(&Employee::name)),
alias_column<als_c>(&Employee::age),
alias_column<als_d>(&Department::dept)),
where(is_equal(alias_column<als_c>(&Employee::id), alias_column<als_d>(&Department::empId))));
Applying aliases to CASE
struct GradeAlias : alias_tag {
static const std::string& get() {
static const std::string res = "Grade";
return res;
}
};
// SELECT ID, NAME, MARKS,
// CASE
// WHEN MARKS >=80 THEN 'A+'
// WHEN MARKS >=70 THEN 'A'
// WHEN MARKS >=60 THEN 'B'
// WHEN MARKS >=50 THEN 'C'
// ELSE 'Sorry!! Failed'
// END as 'Grade'
// FROM STUDENT;
auto rows = storage.select(columns(
&Student::id,
&Student::name,
&Student::marks,
as<GradeAlias>(case_<std::string>()
.when(greater_or_equal(&Student::marks, 80), then("A+"))
.when(greater_or_equal(&Student::marks, 70), then("A"))
.when(greater_or_equal(&Student::marks, 60), then("B"))
.when(greater_or_equal(&Student::marks, 50), then("C"))
.else_("Sorry!! Failed")
.end())));
Changing data
Inserting a single row into a table
INSERT INTO table (column1,column2 ,..) VALUES( value1, value2 ,...);
storage.insert(into<Invoice>(), columns(
&Invoice::id, &Invoice::customerId, &Invoice::invoiceDate),
values(std::make_tuple(1, 1, date("now")))));
Inserting an object
struct User {
int id; // primary key
std::string name;
std::vector<char> hash; // binary format
};
User alex{
0,
"Alex",
{0x10, 0x20, 0x30, 0x40},
};
alex.id = storage.insert(alex); // inserts all non primary key columns, returns primary key when integral
Inserting several rows
storage.insert(into<Invoice>(),
columns(&Invoice::id, &Invoice::customerId, &Invoice::invoiceDate),
values(std::make_tuple(1, 1, date("now")),
std::make_tuple(2, 1, date("now", "+1 year")),
std::make_tuple(3, 1, date("now")),
std::make_tuple(4, 1, date("now", "+1 year"))));
Inserting several objects via containers
If we want to insert or replace a group of persistent atoms, we can insert them into a container and provide iterators to the beginning and end of the desired range of objects, by means of the insert_range or replace_range methods of the storage type. For instance:
std::vector<Department> des =
{
Department{10, "Accounting", "New York"},
Department{20, "Research", "Dallas"},
Department{30, "Sales", "Chicago"},
Department{40, "Operations", "Boston"}
};
std::vector<EmpBonus> bonuses =
{
EmpBonus{-1, 7369, "14-Mar-2005", 1},
EmpBonus{-1, 7900, "14-Mar-2005", 2},
EmpBonus{-1, 7788, "14-Mar-2005", 3}
};
storage.replace_range(des.begin(), des.end());
storage.insert_range(bonuses.begin(), bonuses.end());
Recall that insert like statements do not set the primary keys while replace like statements copy all columns including primary keys. That should explain why we chose to replace the departments because they have explicit primary key values, and why we chose to insert the bonuses letting the database generate the primary key values.
Inserting several rows ( becomes an update if primary key already exists)
// INSERT INTO COMPANY(ID, NAME, AGE, ADDRESS, SALARY)
// VALUES (3, 'Sofia', 26, 'Madrid', 15000.0)
// (4, 'Doja', 26, 'LA', 25000.0)
// ON CONFLICT(ID) DO UPDATE SET NAME = excluded.NAME,
// AGE = excluded.AGE,
// ADDRESS = excluded.ADDRESS,
// SALARY = excluded.SALARY
storage.insert(
into<Employee>(),
columns(&Employee::id, &Employee::name, &Employee::age, &Employee::address, &Employee::salary),
values(
std::make_tuple(3, "Sofia", 26, "Madrid", 15000.0),
std::make_tuple(4, "Doja", 26, "LA", 25000.0)),
on_conflict(&Employee::id)
.do_update(
set(c(&Employee::name) = excluded(&Employee::name),
c(&Employee::age) = excluded(&Employee::age),
c(&Employee::address) = excluded(&Employee::address),
c(&Employee::salary) = excluded(&Employee::salary))));
Inserting only certain columns (provided the rest have either default_values, are nullable, are autoincrement or are generated):
// INSERT INTO Invoices("customerId") VALUES(2), (4), (8)
storage.insert(into<Invoice>(),
columns(&Invoice::customerId),
values(
std::make_tuple(2),
std::make_tuple(4),
std::make_tuple(8)));
// INSERT INTO 'Invoices' ("customerId") VALUES (NULL)
Invoice inv{ -1, 1, std::nullopt };
storage.insert(inv, columns(&Invoice::customerId));
Inserting from select – getting rowid (since primary key is integral)
// INSERT INTO users SELECT "user_backup"."id", "user_backup"."name", "user_backup"."hash" FROM 'user_backup'
storage.insert(into<User>(),
select(columns(&UserBackup::id, &UserBackup::name, &UserBackup::hash))));
auto r = storage.select(last_insert_rowid());
Inserting default values:
storage.insert(into<Artist>(), default_values());
Non-standard extension in SQLITE
Applies to UNIQUE, NOT NULL, CHECK and PRIMARY_KEY constraints, but not to FOREIGN KEY constraints. For insert and update commands10, the syntax is INSERT OR Y or UPDATE OR Y where Y may be any of the following algorithms and the default conflict resolution algorithm is ABORT:
-
ROLLBACK:
- Aborts current statement with SQLITE_CONSTRAINT error and rolls back the current transaction; if no transaction active then behaves as ABORT
-
ABORT
- When constraint violation occurs returns with SQLITE_CONSTRAINT error and the current SQL statement backs out any changes made by it but changes caused by prior statements within the same transaction are preserved and the transaction remains active. This is the default conflict resolution algorithm.
-
FAIL
- Same as abort except that it does not back out prior changes of the current SQL statement… a foreign key constraint causes an ABORT
-
IGNORE
-
Skips the one row that contains the constraint violation and continues processing subsequent rows of the SQL statement as if nothing went wrong: rows before and after the row with constraint violation are inserted or updated normally… a foreign key constraint violation causes an ABORT behavior
-
REPLACE
-
When the constraint violation occurs of the UNIQUE or PRIMARY KEY type, the pre-existing rows causing the violation are deleted prior to inserting or updating the current row and the command continues executing normally. If a NOT NULL violation occurs, the NULL is replaced with the default value for that column if any exists, else the ABORT algorithm is used. For CHECK or foreign key violations, the algorithm works like ABORT. For the deleted rows, the delete triggers (if any) are fired if and only if recursive triggers11 are enabled.
auto rows = storage.insert(or_abort(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_fail(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_ignore(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_replace(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
auto rows = storage.insert(or_rollback(),
into<User>(),
columns(&User::id, &User::name),
values(std::make_tuple(1, "The Weeknd")));
Update
This enables us to update data of existing rows in the table. The general syntax is like this:
UPDATE table SET column_1 = new_value_1, column_2 = new_value_2 WHERE search_condition;
Update several rows
// UPDATE COMPANY SET ADDRESS = 'Texas', SALARY = 20000.00 WHERE AGE < 30
storage.update_all(set(
c(&Employee::address) = "Texas", c(&Employee::salary) = 20000.00),
where(c(&Employee::age) < 30));
// UPDATE contacts
// SET phone = REPLACE12(phone, '410', '+1-410')
storage.update_all(set(
c(&Contact::phone) = replace(&Contact::phone, "410", "+1-410")));
Update one row
// UPDATE products
// SET quantity = 5 WHERE id = 1;
storage.update_all(set(
c(&Product::quantity) = 5),
where(c(&Product::id) == 1));
Update an object
If student exists then update, else insert:
if(storage.count<Student>(where(c(&Student::id) == student.id))) {
storage.update(student);
} else {
studentId = storage.insert(student); // returns primary key
}
auto employee6 = storage.get<Employee>(6);
// UPDATE 'COMPANY' SET "NAME" = val1, "AGE" = val2, "ADDRESS" = “Texas” , "SALARY" = val4 WHERE "ID" = 6
employee6.address = "Texas";
storage.update(employee6); // actually this call updates all non-primary-key columns' values to passed object's
// fields
Delete Syntax
Since delete is a C++ keyword, remove and remove_all are used instead in sqlite_orm. The general syntax for DELETE is in SQL:
DELETE FROM table-name [WHERE expr]
Delete rows that satisfy a condition
// DELETE FROM artist WHERE artistname = 'Sammy Davis Jr.';
storage.remove_all<Artist>(
where(c(&Artist::artistName) == "Sammy Davis Jr."));
Delete all objects of a certain type
// DELETE FROM Customer
storage.remove_all<Customer>();
Delete a certain object by giving its primary key
// DELETE FROM Customer WHERE id = 1;
storage.remove<Customer>(1);
Replace
If we want to set the primary key columns as well as the rest, we need to use replace instead of insert:
User john{
2,
"John",
{0x10, 0x20, 0x30, 0x40},
};
// REPLACE INTO 'Users ("id", "name", "hash") VALUES (2, “John”, {0x10, 0x20, 0x30, 0x40})
storage.replace(john);
Transactions
Transactions
SQLite is transactional in the sense that all changes and queries are atomic, consistent, isolated and durable, better known as ACID:
- Atomic: the change cannot be broken into smaller ones: committing a transaction either applies every statement in it or none at all.
- Consistent: the data must meet all validation rules before and after a transaction
- Isolation: assume 2 transactions executing at the same time attempting to modify the same data. One of the 2 must wait until the other completes in order to maintain isolation
- Durability: consider a transaction that commits but then the program crashes or the operating system crashes or there is a power failure to the computer. A transaction must ensure that the committed changes will persist even under such situations.
Sqlite has some pragmas that define exactly how these transactions are done and what level of durability they offer. For better durability less performance. Please see PRAGMA schema.journal_mode in Pragma statements supported by SQLite… and Write-Ahead Logging (sqlite.org) for detailed discussion.
NOTE: Changes to the database are faster if done within a transaction as in what follows:
storage.begin_transaction();
storage.replace(Employee{
1,
"Adams",
"Andrew",
"General Manager",
{},
"1962-02-18 00:00:00",
"2002-08-14 00:00:00",
"11120 Jasper Ave NW",
"Edmonton",
"AB",
"Canada",
"T5K 2N1",
"+1 (780) 428-9482",
"+1 (780) 428-3457",
"andrew@chinookcorp.com",
});
storage.replace(Employee{
2,
"Edwards",
"Nancy",
"Sales Manager",
std::make_unique<int>(1),
"1958-12-08 00:00:00",
"2002-05-01 00:00:00",
"825 8 Ave SW",
"Calgary",
"AB",
"Canada",
"T2P 2T3",
"+1 (403) 262-3443",
"+1 (403) 262-3322",
"nancy@chinookcorp.com",
});
storage.commit(); // or storage.rollback();
storage.transaction([&storage] {
storage.replace(Student{1, "Shweta", "shweta@gmail.com", 80});
storage.replace(Student{2, "Yamini", "rani@gmail.com", 60});
storage.replace(Student{3, "Sonal", "sonal@gmail.com", 50});
return true; // commits
});
NOTE: use of transaction guard implements RAII idiom
auto countBefore = storage.count<Object>();
try {
auto guard = storage.transaction_guard();
storage.insert(Object{0, "John"});
storage.get<Object>(-1); // throws exception!
REQUIRE(false);
} catch(...) {
auto countNow = storage.count<Object>();
REQUIRE(countBefore == countNow);
}
auto countBefore = storage.count<Object>();
try {
auto guard = storage.transaction_guard();
storage.insert(Object{0, "John"});
guard.commit();
storage.get<Object>(-1); // throws exception but transaction is not rolled back!
REQUIRE(false);
} catch(...) {
auto countNow = storage.count<Object>();
REQUIRE(countNow == countBefore + 1);
}
Core functions
// SELECT name, LENGTH(name)
// FROM marvel
auto namesWithLengths = storage.select(
columns(&MarvelHero::name,
length(&MarvelHero::name))); // namesWithLengths is std::vector<std::tuple<std::string, int>>
// SELECT ABS(points)
// FROM marvel
auto absPoints = storage.select(
abs(&MarvelHero::points)); // std::vector<std::unique_ptr<int>>
cout << "absPoints: ";
for(auto& value: absPoints)
{
if(value) {
cout << *value;
} else {
cout << "null";
}
cout << " ";
}
cout << endl;
// SELECT LOWER(name)
// FROM marvel
auto lowerNames = storage.select(
lower(&MarvelHero::name));
// SELECT UPPER(abilities)
// FROM marvel
auto upperAbilities = storage.select(
upper(&MarvelHero::abilities));
storage.transaction([&] {
storage.remove_all<MarvelHero>();
{ // SELECT changes()
auto rowsRemoved = storage.select(changes()).front();
cout << "rowsRemoved = " << rowsRemoved << endl;
assert(rowsRemoved == storage.changes());
}
{ // SELECT total_changes()
auto rowsRemoved = storage.select(total_changes()).front();
cout << "rowsRemoved = " << rowsRemoved << endl;
assert(rowsRemoved == storage.changes());
}
return false; // rollback
});
// SELECT CHAR(67, 72, 65, 82)
auto charString = storage.select(
char_(67, 72, 65, 82)).front();
cout << "SELECT CHAR(67,72,65,82) = *" << charString << "*" << endl;
// SELECT LOWER(name) || '@marvel.com'
// FROM marvel
auto emails = storage.select(
lower(&MarvelHero::name) || c("@marvel.com"));
// SELECT TRIM(' TechOnTheNet.com ')
auto string = storage.select(
trim(" TechOnTheNet.com ")).front();
// SELECT TRIM('000123000', '0')
storage.select(
trim("000123000", "0")).front()
// SELECT * FROM marvel ORDER BY RANDOM()
for(auto& hero: storage.iterate<MarvelHero>(order_by(sqlite_orm::random()))) {
cout << "hero = " << storage.dump(hero) << endl;
}
NOTE: Use iterate for large result sets because it does not load all the rows into memory
// SELECT ltrim(' TechOnTheNet.com is great!');
storage.select(ltrim(" TechOnTheNet.com is great!")).front();
Core functions can be used within prepared statements:
auto lTrimStatement = storage.prepare(select(
ltrim("000123", "0")));
// SELECT ltrim('123123totn', '123');
get<0>(lTrimStatement) = "123123totn";
get<1>(lTrimStatement) = "123";
cout << "ltrim('123123totn', '123') = " << storage.execute(lTrimStatement).front() << endl;
// SELECT rtrim('TechOnTheNet.com ');
cout << "rtrim('TechOnTheNet.com ') = *" << storage.select(rtrim("TechOnTheNet.com ")).front() << "*" << endl;
// SELECT rtrim('123000', '0');
cout << "rtrim('123000', '0') = *" << storage.select(rtrim("123000", "0")).front() << "*" << endl;
// SELECT coalesce(NULL,20);
cout << "coalesce(NULL,20) = " << storage.select(coalesce<int>(std::nullopt, 20)).front() << endl;
cout << "coalesce(NULL,20) = " << storage.select(coalesce<int>(nullptr, 20)).front() << endl;
// SELECT substr('SQLite substr', 8);
cout << "substr('SQLite substr', 8) = " << storage.select(substr("SQLite substr", 8)).front() << endl;
// SELECT substr('SQLite substr', 1, 6);
cout << "substr('SQLite substr', 1, 6) = " << storage.select(substr("SQLite substr", 1, 6)).front() << endl;
// SELECT hex(67);
cout << "hex(67) = " << storage.select(hex(67)).front() << endl;
// SELECT quote('hi')
cout << "SELECT quote('hi') = " << storage.select(quote("hi")).front() << endl;
// SELECT hex(randomblob(10))
cout << "SELECT hex(randomblob(10)) = " << storage.select(hex(randomblob(10))).front() << endl;
// SELECT instr('something about it', 't')
cout << "SELECT instr('something about it', 't') = " << storage.select(instr("something about it", "t")).front();
struct o_pos : alias_tag {
static const std::string& get() {
static const std::string res = "o_pos";
return res;
}
};
// SELECT name, instr(abilities, 'o') o_pos
// FROM marvel
// WHERE o_pos > 0
auto rows = storage.select(columns(
&MarvelHero::name, as<o_pos>(instr(&MarvelHero::abilities, "o"))),
where(greater_than(get<o_pos>(), 0)));
// SELECT replace('AA B CC AAA','A','Z')
cout << "SELECT replace('AA B CC AAA','A','Z') = " << storage.select(replace("AA B CC AAA", "A", "Z")).front();
// SELECT replace('This is a cat','This','That')
cout << "SELECT replace('This is a cat','This','That') = "
<< storage.select(replace("This is a cat", "This", "That")).front() << endl;
// SELECT round(1929.236, 2)
cout << "SELECT round(1929.236, 2) = " << storage.select(round(1929.236, 2)).front() << endl;
// SELECT round(1929.236, 1)
cout << "SELECT round(1929.236, 1) = " << storage.select(round(1929.236, 1)).front() << endl;
// SELECT round(1929.236)
cout << "SELECT round(1929.236) = " << storage.select(round(1929.236)).front() << endl;
// SELECT unicode('A')
cout << "SELECT unicode('A') = " << storage.select(unicode("A")).front() << endl;
// SELECT typeof(1)
cout << "SELECT typeof(1) = " << storage.select(typeof_(1)).front() << endl;
// SELECT firstname, lastname, IFNULL(fax, 'Call:' || phone) fax
// FROM customers ORDER BY firstname
auto rows = storage.select(columns(
&Customer::firstName, &Customer::lastName,
ifnull<std::string>(&Customer::fax, "Call:" || c(&Customer::phone))),
order_by(&Customer::firstName));
cout << "SELECT last_insert_rowid() = " << storage.select(last_insert_rowid()).front() << endl;
Data definition
Sqlite data types
SQLITE uses dynamic type system: the value stored in a column determines its data type, not the column’s data type. You can even declare a column without specifying a data type. However columns created by sqlite_orm do have a declared data type. SQLite provides primitive data types we call storage classes which are more general than a data type: INTEGER storage class includes 6 different types of integers.
| Storage class | Meaning |
|---|---|
| NULL | NULL values mean missing information or unknown |
| Integer | Whole numbers vith variable sizes such as 1,2,3,4 or 8 bytes |
| REAL | Real numbers with decimal values using 8 byte floats |
| TEXT | Stores character data of unlimited length. Supports various character encodings |
| BLOB | Binary large object that can store any kind of data of any length |
The data type of a value is taken by these rules:
- If a literal has no enclosing quotes and decimal point or exponent, SQLite assigns the INTEGER storage class
- If a literal is inclosed by single or double quotes, SQLite assigns the TEXT storage class
- If a literal does not have quotes nor decimal points nor exponent, SQLite assigns the REAL storage class
- If a literal is NULL without quotes, it is assigned a NULL storage class
- If a literal has the format X’ABCD’ or x’ábcd’ SQLIte assignes BLOB storage class. • Date and time can be stored as TEXT, INTEGER or REAL
How is data sorted when there are different storage classes?
Following these rules:
- NULL storage class has the lowest value… between NULL values there is no order
- The next higher storage classes are INTEGER and REAL, comparing them numerically
- The next higher storage class is TEXT, comparing them according to collation
- Highest storage class is BLOB, using the C function memcmp() to compare BLOB values
When using ORDER BY 2 steps are followed:
- Group values based on storage class: NULL, INTEGER, REAL, TEXT, BLOB
- Sort the values in each group
Therefore, even if the engine allows different types in one column, it is not a good idea!
Manifest typing and type affinity
- Manifest typing means that a data type is a property of a value stored in a column, not the property of the column in which the value is stored.. values of any type can be stored in a column
- Type affinity is the recommended type for data stored in that column – recommended, not required
SELECT typeof(100), typeof(10.0), typeof('100'), typeof(x'1000'), typeof(NULL);
In sqlite_orm typeof is typeof_.
Create table
In sqlite_orm we create the tables, indices, unique constraints, check constraints and triggers using the make_storage() function. Each data field of the struct we want to persist is mapped to one column in the table – but we don’t have to add all of them: a struct may have non-storable fields. So first we define the types, normalize13 them and create the structs. These structs can be called “persistent atoms”.
struct User {
int id;
std::string name;
std::vector<char> hash; // binary format
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("blob.sqlite",
make_table("users",
make_column("id", &User::id),
make_column("name", &User::name, default_value(“?”)),
make_column("hash", &User::hash)));
storage.sync_schema();
}
This creates a database with name blob.sqlite and one table called users with 3 columns. The sync_schema() synchronizes the schema with the database but does not always work for existing tables. A workaround is to drop the tables and start the schema from cero. Adding uniqueness constraints to existing tables usually won’t work… you need to version tables for doing some schema changes. It also defines a default value for column “name”.
CHECK constraint
Ensure values in columns meet specified conditions defined by an expression:
struct Contact {
int id = 0;
std::string firstName;
std::string lastName;
std::string email;
std::string phone;
};
struct Product {
int id = 0;
std::string name;
float listPrice = 0;
float discount = 0;
};
auto storage = make_storage(":memory:",
make_table("contacts",
make_column("contact_id", &Contact::id),
make_column("first_name", &Contact::firstName),
make_column("last_name", &Contact::lastName),
make_column("email", &Contact::email),
make_column("phone", &Contact::phone),
check(length(&Contact::phone) >= 10)),
make_table("products",
make_column("product_id", &Product::id, primary_key()),
make_column("product_name", &Product::name),
make_column("list_price", &Product::listPrice),
make_column("discount", &Product::discount, default_value(0)),
check(c(&Product::listPrice) >= &Product::discount and
c(&Product::discount) >= 0 and c(&Product::listPrice) >= 0)));
storage.sync_schema();
This adds a check constraint and a column with default value.
Columns with specific collation and tables with Primary Key
struct User {
int id;
std::string name;
time_t createdAt;
};
struct Foo {
std::string text;
int baz;
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage(
"collate.sqlite",
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name),
make_column("created_at", &User::createdAt)),
make_table("foo", make_column("text", &Foo::text, collate_nocase()), make_column("baz", &Foo::baz)));
storage.sync_schema();
}
This creates a case insensitive text column (other collations exist: collate_rtrim and collate_binary).
FOREIGN KEY constraint
struct Artist {
int artistId;
std::string artistName;
};
struct Track {
int trackId;
std::string trackName;
std::optional<int> trackArtist; // must map to &Artist::artistId
};
int main(int, char** argv) {
cout << "path = " << argv[0] << endl;
using namespace sqlite_orm;
{ // simple case with foreign key to a single column without actions
auto storage = make_storage("foreign_key.sqlite",
make_table("artist",
make_column("artistid", &Artist::artistId, primary_key()),
make_column("artistname", &Artist::artistName)),
make_table("track",
make_column("trackid", &Track::trackId, primary_key()),
make_column("trackname", &Track::trackName),
make_column("trackartist", &Track::trackArtist),
foreign_key(&Track::trackArtist).references(&Artist::artistId)));
auto syncSchemaRes = storage.sync_schema();
for (auto& p : syncSchemaRes) {
cout << p.first << " " << p.second << endl;
}
}
}
This one defines a simple foreign key.
struct User {
int id;
std::string firstName;
std::string lastName;
};
struct UserVisit {
int userId;
std::string userFirstName;
time_t time;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage(
{},
make_table("users",
make_column("id", &User::id, primary_key()),
make_column("first_name", &User::firstName),
make_column("last_name", &User::lastName),
primary_key(&User::id, &User::firstName)),
make_table("visits",
make_column("user_id", &UserVisit::userId),
make_column("user_first_name", &UserVisit::userFirstName),
make_column("time", &UserVisit::time),
foreign_key(&UserVisit::userId, &UserVisit::userFirstName)
.references(&User::id, &User::firstName)));
storage.sync_schema();
}
This defines a compound foreign key and a corresponding compound primary key.
AUTOINCREMENT property
struct DeptMaster {
int deptId = 0;
std::string deptName;
};
struct EmpMaster {
int empId = 0;
std::string firstName;
std::string lastName;
long salary;
decltype(DeptMaster::deptId) deptId;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage("", // empty db name means in memory db
make_table("dept_master",
make_column("dept_id", &DeptMaster::deptId, primary_key(), autoincrement()),
make_column("dept_name", &DeptMaster::deptName)),
make_table("emp_master",
make_column("emp_id", &EmpMaster::empId, autoincrement(), primary_key()),
make_column("first_name", &EmpMaster::firstName),
make_column("last_name", &EmpMaster::lastName),
make_column("salary", &EmpMaster::salary),
make_column("dept_id", &EmpMaster::deptId)));
storage.sync_schema();
}
This defines both primary keys to be autoincrement(), so if you do not specify aa value for the primary key one is created in a sequence. You may also determine the primary key explicitly using replace.
GENERATED COLUMNS
struct Product {
int id = 0;
std::string name;
int quantity = 0;
float price = 0;
float totalValue = 0;
};
auto storage = make_storage({},
make_table("products",
make_column("id", &Product::id, primary_key()),
make_column("name", &Product::name),
make_column("quantity", &Product::quantity),
make_column("price", &Product::price),
make_column("total_value",&Product::totalValue,
generated_always_as(&Product::price * c(&Product::quantity)))));
storage.sync_schema();
This defines a generated column!
Databases may be created in memory if desired
By using the special name “:memory:” or just an empty name, SQLITE is instructed to create the database in memory.
struct RapArtist {
int id;
std::string name;
};
int main(int, char**) {
auto storage = make_storage(":memory:",
make_table("rap_artists",
make_column("id", &RapArtist::id, primary_key()),
make_column("name", &RapArtist::name)));
cout << "in memory db opened" << endl;
storage.sync_schema();
}
This one is stored in memory (can also leave the dbname empty to achieve the same effect).
INDEX and UNIQUE INDEX
struct Contract {
std::string firstName;
std::string lastName;
std::string email;
};
using namespace sqlite_orm;
// beware - put `make_index` before `make_table` cause `sync_schema` is called in reverse order
// otherwise you'll receive an exception
auto storage = make_storage(
"index.sqlite",
make_index("idx_contacts_name", &Contract::firstName, &Contract::lastName,
where(length(&Contract::firstName) > 2)),
make_unique_index("idx_contacts_email", indexed_column(&Contract::email).collate("BINARY").desc()),
make_table("contacts",
make_column("first_name", &Contract::firstName),
make_column("last_name", &Contract::lastName),
make_column("email", &Contract::email)));
This one allows you to create an index and a unique index.
DEFAULT VALUE for DATE columns
struct Invoice
{
int id;
int customerId;
std::optional<std::string> invoiceDate;
};
using namespace sqlite_orm;
int main(int, char** argv) {
cout << argv[0] << endl;
auto storage = make_storage("aliases.sqlite",
make_table("Invoices", make_column("id", &Invoice::id, primary_key(), autoincrement()),
make_column("customerId", &Invoice::customerId),
make_column("invoiceDate", &Invoice::invoiceDate, default_value(date("now")))));
this one defines the default value of invoiceDate to be the current date at the moment of insertion.
PERSISTENT collections
/**
* This is just a mapped type.
*/
struct KeyValue {
std::string key;
std::string value;
};
auto& getStorage() {
using namespace sqlite_orm;
static auto storage = make_storage("key_value_example.sqlite",
make_table("key_value",
make_column("key", &KeyValue::key, primary_key()),
make_column("value", &KeyValue::value)));
return storage;
}
void setValue(const std::string& key, const std::string& value) {
using namespace sqlite_orm;
KeyValue kv{key, value};
getStorage().replace(kv);
}
std::string getValue(const std::string& key) {
using namespace sqlite_orm;
if(auto kv = getStorage().get_pointer<KeyValue>(key)) {
return kv->value;
} else {
return {};
}
}
Implements a persistent map.
GETTERS and SETTERS
class Player {
int id = 0;
std::string name;
public:
Player() {}
Player(std::string name_) : name(std::move(name_)) {}
Player(int id_, std::string name_) : id(id_), name(std::move(name_)) {}
std::string getName() const {
return this->name;
}
void setName(std::string name) {
this->name = std::move(name);
}
int getId() const {
return this->id;
}
void setId(int id) {
this->id = id;
}
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("private.sqlite",
make_table(“players",
make_column("id",
&Player::setId, // setter
&Player::getId, // getter
primary_key()),
make_column("name",
&Player::getName, // order between setter and getter doesn't matter.
&Player::setName)));
storage.sync_schema();
}
This one uses getters and setters (note the order does not matter).
DEFINING THE SHEMA FOR SELF-JOINS
struct Employee {
int employeeId;
std::string lastName;
std::string firstName;
std::string title;
std::unique_ptr<int> reportsTo; // can also be std::optional<int> for nullable columns
std::string birthDate;
std::string hireDate;
std::string address;
std::string city;
std::string state;
std::string country;
std::string postalCode;
std::string phone;
std::string fax;
std::string email;
};
int main() {
using namespace sqlite_orm;
auto storage = make_storage("self_join.sqlite",
make_table("employees",
make_column("EmployeeId", &Employee::employeeId, autoincrement(), primary_key()),
make_column("LastName", &Employee::lastName),
make_column("FirstName", &Employee::firstName),
make_column("Title", &Employee::title),
make_column("ReportsTo", &Employee::reportsTo),
make_column("BirthDate", &Employee::birthDate),
make_column("HireDate", &Employee::hireDate),
make_column("Address", &Employee::address),
make_column("City", &Employee::city),
make_column("State", &Employee::state),
make_column("Country", &Employee::country),
make_column("PostalCode", &Employee::postalCode),
make_column("Phone", &Employee::phone),
make_column("Fax", &Employee::fax),
make_column("Email", &Employee::email),
foreign_key(&Employee::reportsTo).references(&Employee::employeeId)));
storage.sync_schema();
}
SUBENTITIES
class Mark {
public:
int value;
int student_id;
};
class Student {
public:
int id;
std::string name;
int roll_number;
std::vector<decltype(Mark::value)> marks;
};
using namespace sqlite_orm;
auto storage = make_storage("subentities.sqlite",
make_table("students",
make_column("id", &Student::id, primary_key()),
make_column("name", &Student::name),
make_column("roll_no", &Student::roll_number)),
make_table("marks",
make_column("mark", &Mark::value),
make_column("student_id", Mark::student_id),
foreign_key(&Mark::student_id).references(&Student::id)));
// inserts or updates student and does the same with marks
int addStudent(const Student& student) {
auto studentId = student.id;
if(storage.count<Student>(where(c(&Student::id) == student.id))) {
storage.update(student);
} else {
studentId = storage.insert(student);
}
// insert all marks within a transaction
storage.transaction([&] {
storage.remove_all<Mark>(where(c(&Mark::student_id) == studentId));
for(auto& mark: student.marks) {
storage.insert(Mark{mark, studentId});
}
return true;
});
return studentId;
}
/**
* To get student from db we have to execute two queries:
* `SELECT * FROM students WHERE id = ?`
* `SELECT mark FROM marks WHERE student_id = ?`
*/
Student getStudent(int studentId) {
auto res = storage.get<Student>(studentId);
res.marks = storage.select(&Mark::value, where(c(&Mark::student_id) == studentId));
return res; // must be moved automatically by compiler
}
This one implements a sub-entity.
UNIQUENESS AT THE COLUMN AND TABLE LEVEL
struct Entry {
int id;
std::string uniqueColumn;
std::unique_ptr<std::string> nullableColumn;
};
int main(int, char**) {
using namespace sqlite_orm;
auto storage = make_storage("unique.sqlite",
make_table("unique_test",
make_column("id", &Entry::id, autoincrement(), primary_key()),
make_column("unique_text", &Entry::uniqueColumn, unique()),
make_column("nullable_text", &Entry::nullableColumn),
unique(&Entry::id, &Entry::uniqueColumn)));
this one implements uniqueness at the column and table levels.
NOT NULL CONSTRAINT
Every data field of a persistent struct is by default not null. If we desire to allow nulls in a column, the type for the corresponding field must be one of these:
- Std::unique_ptr
- Std::shared_ptr
- Std::optional
VACUUM
Why do we need vacuum?
- Dropping database objects such as tables, views, indexes, or triggers marks them as free but the database size does not decrease.
- Every time you insert or delete data from tables, the index and tables become fragmented
- Insert, update and delete operations reduces the number of rows that can be stored in a single page => increases the number of pages necessary to hold a table => decreases cache performance and time to read/write
- Vacuum defragments the database objects, repacks individual pages ignoring the free spaces – it rebuilds the database and enables one to change database specific configuration parameters such as page size, page format and default encoding… just set new values using pragma and proceed with vacuum.
storage.vacuum();
Triggers
What is a Trigger?
A named database code that is executed automatically when an INSERT, UPDATE or DELETE statement is issued against the associated table.
Why do we need them?
- Auditing: log the changes in sensitive data (e.g. salary, email)
- To enforce complex business rules at the database level and prevent invalid transactions
Syntax:
CREATE TRIGGER [IF NOT EXISTS] trigger_name
[BEFORE|AFTER|INSTEAD OF14] [INSERT|UPDATE|DELETE]
ON table_name
[WHEN condition]
BEGIN
statements;
END;
Accessing old and new column values according to action
| Action | Availability |
|---|---|
| INSERT | NEW is available |
| UPDATE | Both NEW and OLD are available |
| DELETE | OLD is available |
Examples of Triggers
// CREATE TRIGGER validate_email_before_insert_leads
// BEFORE INSERT ON leads
// BEGIN
// SELECT
// CASE
// WHEN NEW.email NOT LIKE '%_@__%.__%' THEN
// RAISE (ABORT,'Invalid email address')
// END;
// END;
make_trigger("validate_email_before_insert_leads",
before()
.insert()
.on<Lead>()
.begin(select(case_<int>()
.when(not like(new_(&Lead::email), "%_@__%.__%"),
then(raise_abort("Invalid email address")))
.end()))
.end())
// CREATE TRIGGER log_contact_after_update
// AFTER UPDATE ON leads
// WHEN old.phone <> new.phone
// OR old.email <> new.email
// BEGIN
// INSERT INTO lead_logs (
// old_id,
// new_id,
// old_phone,
// new_phone,
// old_email,
// new_email,
// user_action,
// created_at
// )
// VALUES
// (
// old.id,
// new.id,
// old.phone,
// new.phone,
// old.email,
// new.email,
// 'UPDATE',
// DATETIME('NOW')
// ) ;
// END;
make_trigger("log_contact_after_update",
after()
.update()
.on<Lead>()
.when(is_not_equal(old(&Lead::phone), new_(&Lead::phone)) and
is_not_equal(old(&Lead::email), new_(&Lead::email)))
.begin(insert(into<LeadLog>(),
columns(&LeadLog::oldId,
&LeadLog::newId,
&LeadLog::oldPhone,
&LeadLog::newPhone,
&LeadLog::oldEmail,
&LeadLog::newEmail,
&LeadLog::userAction,
&LeadLog::createdAt),
values(std::make_tuple(
old(&Lead::id),
new_(&Lead::id),
old(&Lead::phone),
new_(&Lead::phone),
old(&Lead::email),
new_(&Lead::email),
"UPDATE",
datetime("NOW")))))
.end())
// CREATE TRIGGER validate_fields_before_insert_fondos
// BEFORE INSERT
// ON Fondos
// BEGIN
// SELECT CASE WHEN NEW.abrev = '' THEN RAISE(ABORT, "Fondo abreviacion empty") WHEN LENGTH(NEW.nombre) = 0 // THEN
RAISE(ABORT, "Fondo nombre empty") END;
// END;
make_trigger("validate_fields_before_insert_fondos",
before()
.insert()
.on<Fondo>()
.begin(select(case_<int>()
.when(is_equal(new_(&Fondo::abreviacion),""),
then(raise_abort("Fondo abreviacion empty")))
.when(is_equal(length(new_(&Fondo::nombre)), 0),
then(raise_abort("Fondo nombre empty")))
.end()))
.end())
// CREATE TRIGGER validate_fields_before_update_fondos
// BEFORE UPDATE
// ON Fondos
// BEGIN
// SELECT CASE WHEN NEW.abrev = '' THEN RAISE(ABORT, "Fondo abreviacion empty") WHEN LENGTH(NEW.nombre) = 0 // THEN
RAISE(ABORT, "Fondo nombre empty") END;
// END;
make_trigger("validate_fields_before_update_fondos",
before()
.update()
.on<Fondo>()
.begin(select(case_<int>()
.when(is_equal(new_(&Fondo::abreviacion), ""),
then(raise_abort("Fondo abreviacion empty")))
.when(is_equal(length(new_(&Fondo::nombre)), 0),
then(raise_abort("Fondo nombre empty")))
.end()))
.end())
Data migration
Sqlite_orm supports automatic schema migration to a certain degree but there are a few caveats. Currently you can make changes to the storage schema and call storage.sync_schema(true) which will attempt to apply the current schema to the database. There are limits to what it can do and currently we do not support data migration primitives like add_column(), drop_column(), etc. However, the sync_schema method will attempt to detect the changes between the storage schema and the database schema and try to reconcile without data loss most of the time. There are however very clear exceptions, and we are working on them. First, not all attributes of a column nor attributes of a table are compared to the database schema. This is currently a limitation of the table_xinfo pragma of sqlite3, not of sqlite_orm itself. Second, there is a common source of problems with the foreign key checking mechanism that makes it very difficult to do backups of tables that need to be dropped and recreated. As it happens, when a table has dependent rows, it cannot normally be dropped. There are only two solutions that we know of at present: one is to remove all foreign key constraints of tables towards the table at hand temporarily using a sqlite client like SqliteStudio or DB Browser for Sqlite (see the section on tools). This will allow the backing up of the current table since that process requires a drop table as one of its steps. The other method is controversial but used by these tools and some developers to simplify the process. It has to do with disabling FK checking before doing the backup and restoring it immediately afterwards. This does not require to remove the foreign key constraints that target the table at hand. For more detailed information about how to automate the schema migration process, please feel free to get in contact with the author (see my details at the end of the document). If data preservation and schema evolution are important to you, you need this additional information. What are the aspects of a column that are comparable to the database schema? First, whether the column is part of the primary key of the table. Second, whether the column has a default value. Third, whether the column is nullable (i.e. if it accepts null values). Fourth, whether the column is hidden (meaning the column is generated_always_as()). Period. All other changes, like what the default value of the column is, or what the generated value of the column is, or whether the column is unique, or has a check constraint, are simply not detected when compared with the physical database schema. For a change in any of these properties to be incorporated at the physical database, we require to drop and recreate the table. The easiest and more secure way to provoke this behavior is to remove the primary key constraint of a table temporarily: this will ensure the drop and recreation of the table using a backup, preserving the data. Putting aside how we deal with foreign key constraints, be it by means of sqlite client tools or at the database configuration level, the essence of data preservation and schema evolution deals with provoking a drop and recreate of the table at hand with a backup process in place. What actions on the storage schema are detected by sync_schema and how exactly does it respond? This next section deals with this topic.
Schema Actions Detected by sync_schema()
- Adding a column to the storage schema that does not exist in the database
- If the column has no default value nor is nullable nor is generated, then there is no way data in that table can be preserved. Just think about it: what value could be inserted in that column for each existing row?
- This is therefore strictly prohibited unless you do not care about losing the table’s data. If you wish to add such a column you must first add a lossless column (see next) and then tweak its properties as you like (thus a two-step process is unavoidable)
- If the column has a default value, is nullable or is generated15, then there will be a ALTER TABLE ADD COLUMN command that is efficient and effective. There will be no loss of table’s data and no backup will be needed
- sync_schema_simulate(true) will return sync_schema_result::new_columns_added for that table
- If the column has no default value nor is nullable nor is generated, then there is no way data in that table can be preserved. Just think about it: what value could be inserted in that column for each existing row?
- Removing a column from storage schema that exists in the database
- An ALTER TABLE DROP COLUMN command will be issued and no data loss will occur
- Remove primary key constraint16 on a table
- This will generate a drop and recreate with backup, thus no data loss will occur
- Adding a primary key constraint on a table
- This will generate a drop and recreate with backup, thus no data loss will occur
- Adding nullability to a column
- This will generate a drop and recreate with backup, thus no data loss will occur
- Removing nullability to a column
- This will generate a drop and recreate with backup, thus no data loss will occur but
- Make sure every existing row has a value distinct from null in this column prior to removing nullability, otherwise an exception will occur and interrupt the update process, rolling it back to the initial state
- This will generate a drop and recreate with backup, thus no data loss will occur but
- Adding or removing a default value to a column
- This will generate a drop and recreate with backup, thus no data loss will occur
Schema Actions Not Detected by sync_schema()
- Changing the default value of a column that already had a default value
- Will go unnoticed
- Changing the generated value of a column that already was generated
- Will go unnoticed
- Adding or removing a check clause to a column or a table
- Will go unnoticed
- If you provoke the drop and recreation with backup by toggling the primary key constraint, for example, then you must ensure that the existing rows pass the check clause if adding one or else the process will be rollbacked to initial state
- Adding or removing a unique clause to a column or a table (more than one column)
- Will go unnoticed
- If you provoke the drop and recreation with backup by toggling the primary key constraint, for example, then you must ensure that the column’s values are distinct if adding a unique clause otherwise you should not be concerned if removing uniqueness
- Adding or removing foreign key constraints
- Will go unnoticed
Aspects to Consider when Synching a Schema
The method storage.sync_schema(true) tries to synchronize the on memory schema (called the storage schema) defined by the make_storage call, with the database schema. We are going to explore what this method can handle and what changes it takes care of and what changes it doesn’t and what to do when it is not enough for our needs17. When we don’t care about the data and only want to synchronize schema, then use storage.sync_schema(false).
- Tables present in the database are not altered in any way nor dropped if they are not mentioned in the make_table() calls of make_storage() – therefore your C++ project is capable of dealing with a subset of the tables in a database if desired
- Every table from storage is compared with its database analog and the following rules determine the outcome:
- If table does not exist, it will be created
- If table exists with excess columns the table will drop the columns to match those defined in storage schema
- If table exists with less columns, the table will add the columns to match those defined in storage schema
- If the difference in schemas is a detectable one (see above), then if sync_schema(true) is called data will be preserved
- Otherwise, the difference between schemas will remain in conflict
- For differences not detected between storage and database schemas, it will be necessary to provoke the drop and recreation of the table; this can be accomplished by one of the following:
- Change nullability of a column: if removing nullability make sure there are no null values in the column’s rows prior to triggering
- Change the presence of a default value of a column (if temporary, remember to restore)
- Change the primary key constraint of a column (you must restore it afterwards!)
- Add a generated column of the stored type (be sure to remove it afterwards!)
About correct order of removing FK by using a sqlite client tool
- If we have a table that we need to drop and recreate with backup, to synchronize its schema, we must remove the FK from the tables that target it
- Then we proceed to trigger the drop and recreate with backup by running sync_schema(true)
- After which we restore the FK constraints by using the sqlite client tool in all tables we had removed the FK
With this approach, we handle the FK constraints by means of a sqlite client tool18
Using SqliteStudio for FK removal/restore
Suppose we need to drop/recreate the Dept table which has dependent rows in table Emp. Before we trigger the drop/recreate, we need to remove the FK constraint from the Emp table to be restored after applying the schema changes to Dept. The process is illustrated below:
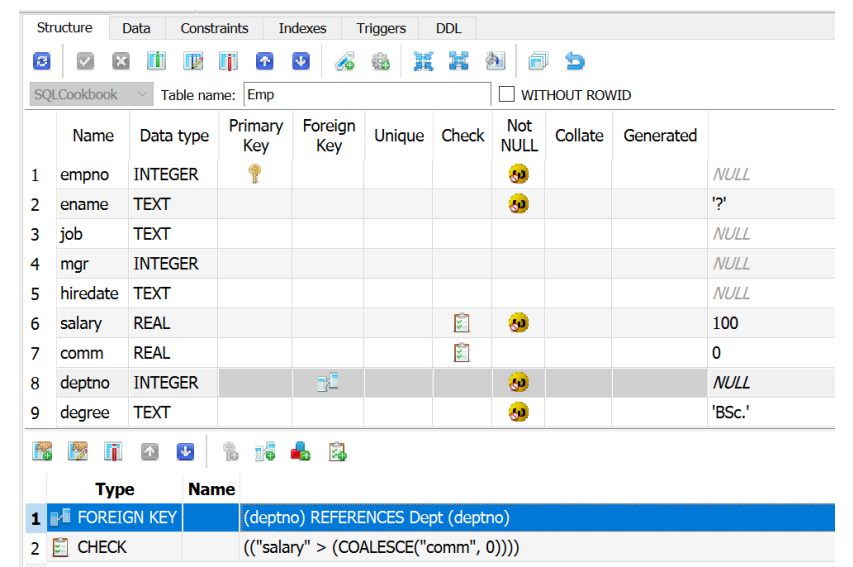
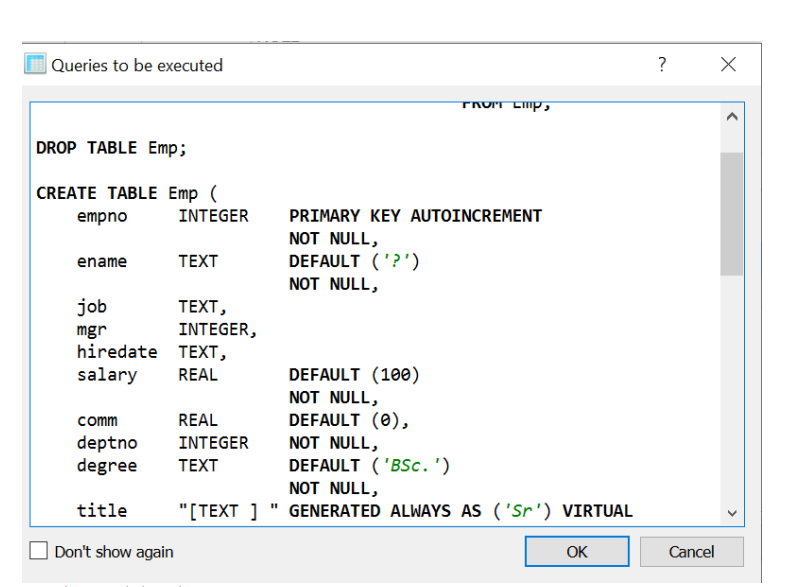
Accept the proposed schema changes
About correct order of dropping/loading tables1
Another approach to reapplying schema changes is to load the contents of each table into vectors20 and drop each table with storage.drop_table(). Then drop all in an order that guarantees the absence of dependent rows, and recreate the tables by calling storage.sync_schema(). The order will be determined by the following algorithm: We must create a graph of all tables connected by edges from the table with a foreign key to a table referenced by that foreign key and start dropping from the leaves. We will recreate all tables and reload them in inverse order from that used in the dropping.
Example
Consider a simple schema with two tables, one for User and one for Job and suppose we want to drop and recreate them (or sync_schema is going to try doing this for us). We must be sure that tables with dependent rows do not exist when the referenced table is dropped, else we will get an exception.
static auto storage = make_storage(dbFilePath,
make_unique_index("name_unique.idx", &User::name ),
make_table("user_table",
make_column("id", &User::id, primary_key()),
make_column("name", &User::name),
make_column("born", &User::born),
make_column("job", &User::job),
make_column("blob", &User::blob),
make_column("age", &User::age ),
check(length(&User::name) > 2),
check(c(&User::born) != 0),
foreign_key(&User::job).references(&Job::id)),
make_table("job",
make_column("id", &Job::id, primary_key(), autoincrement()),
make_column("name", &Job::name, unique()),
make_column("base_salary", &Job::base_salary)));
Now load and drop tables in correct order:
std::vector<User> users = storage.get_all<User>();
storage.drop_table(storage.tablename<User>());
std::vector<Job> jobs = storage.get_all<Job>();
storage.drop_table(storage.tablename<Job>());
now call sync_schema() to propagate changes to database:
auto m = storage.sync_schema(false); // we may inspect the return ‘m’ for information of actions performed
and reload tables in correct order (inverse of that used in dropping):
storage.replace_range(jobs.begin(), jobs.end());
storage.replace_range(users.begin(), users.end());
How to drop data without losing it
When we have a difference between the storage schema and the database that is detectable by the sync_schema() function and it triggers table to be dropped and recreated or when the difference is not detectable we must do the following to keep schemas synchronized:
- Call make_storage()
- If the change would add a column that is not nullable and does not have a default value nor is generated, then consider creating an intermediate column with one of these properties and then change the properties; do not add such a column in only one step because you will lose all the table data!
- Load all data from the transitive dependent tables of the current table and the current table in the order specified by About correct order of dropping/loading tables21
- If case is moving from a non-nullable to nullable column decide what (if at all) we are going to interpret as null values and modify the loaded data to change them to null values as described in Interpret values in non-nullable column as nullable
- Drop tables in order given by point 2 above
- Call sync_schema(false) – we are not using the backup feature of sync_schema() so use false as an argument
- Replace all data into tables from the std::vectors in reverse order from that in which we dropped them
Interpret values in non-nullable column as nullable
If we are adding nullable to an existing column that is not nullable in the database, then we need to decide if we are going to interpret certain values as nullable and modify the vector’s elements.
- For instance: a. For integer or real, is 0 to be taken as null?
- For text, is “” to be taken as null?
- For blob, is size() of std::vector == 0 to be taken as null?
- If we decide these values should be treated as nulls, then we must transform the nullable column to std::nullopt following this pattern before replacing the vector into the table. For instance if the type of column job is integer or real, then we check whether its value is 0 and if so we replace it with std::nullopt which is interpreted as NULL in SQL:
std::transform(users.begin(), users.end(), users.begin(), [](User& user)
{
if (user.job && user.job.value() == 0) { user.job = std::nullopt; } return user;
});
Making a backup of the entire database
template<typename T>
void backup_db(T& storage, std::string db_name)
{
namespace fs = std::filesystem;
auto path_to_db_name = fs::path(db_name);
auto stem = path_to_db_name.stem().string();
auto backup_stem = stem + "_backup1.sqlite";
auto backup_full_path = path_to_db_name.parent_path().append(backup_stem).string();
storage.backup_to(backup_full_path);
}
Ensuring that a column contains unique values before making the column unique
If we have a persistent struct User with a column age which we want to declare unique, we must first detect if there are duplicates in the table. Consider:
- loading the table into a vector
- sorting the table by age
- find if there are repeated values by using adjacent_find algorithm
- compare return value to end iterator of vector: if it is different then we have a duplicate which we must correct!
The code could be like this:
std::vector<User> users = storage.get_all<User>();
std::sort(users.begin(), users.end(), [](const User& l, const User& r) { return l.age < r.age; });
auto it = std::adjacent_find(users.begin(),users.end(),[](const User& l, const User& r) { return l.age == r.age; });
if( it!= users.end()) {
// there are duplicates!
User user = *it; // points to duplicate
auto age = user.age; // duplicate age
}
SQLite tools
SQLiteStudio and Sqlite3 command shell
GUI open source full featured SQLite client downloadable from SQLiteStudio, runs on Windows, Linux and MacOS X written in C++ using Qt 5.15.2 and SQLite 3.35.4.
Sqlite3.exe command shell and other command line utilities and even source code downloadable from SQLite Download Page.
Installing the sqlite_orm library and DSL
Go to fnc12/sqlite_orm: ❤SQLite ORM light header only library for modern C++ (github.com) and click the green button called Code. Copy the URL under the HTTPS tab. Open a command line22 terminal and navigate to the destination directory of your choice. There write the following commands:
- git clone https://github.com/fnc12/sqlite_orm.git
- git checkout dev
- Any project that wants to use sqlite_orm DSL will require the include path to contain %INSTALLATION_DIR%/include
To build the C++ projects for unit-testing in Windows OS do the following:
- Execute CMake-Gui from the Start Menu
- Use your folder where you placed the source code and create a directory for the binaries (here I have chosen an out of project directory called sqlite_orm_binary).
- Press configure button. You will get an error regarding the location of sqlite3.h and sqlite3.lib like this:
CMake Error at C:/Program Files/CMake/share/cmake-3.22/Modules/FindPackageHandleStandardArgs.cmake:230 (message): Could NOT find SQLite3 (missing: SQLite3_INCLUDE_DIR SQLite3_LIBRARY)
- Press the right hand button on the SQLite3_INCLUDE_DIR and locate the path where sqlite3.h is found, for example:

- Then press the right hand button on the SQLite3_LIBRARY and locate the sqlite3.lib, for example:
- **Press Configure again. It should compile without errors. **
- Press Generate and the binaries will be created in the binary chosen folder.
- You can now go to that folder and open a Visual Studio 2022 .sln file that contains all the unit-tests called: sqlite_orm.sln
- Open that file in VS 2022 and compile it and run the tests… Everything should work as expected.
- Your library is now available for use.
Installing SQLite using vcpkg in Windows
Microsoft offers a tool for open source library management called Microsoft/vcpkg available at microsoft/vcpkg: C++ Library Manager for Windows, Linux, and MacOS (github.com) and installable by following instructions at microsoft/vcpkg: C++ Library Manager for Windows, Linux, and MacOS (github.com). After installed, run at the command line the following:
\> .\vcpkg\vcpkg install sqlite3:x64-windows
When you open Visual Studio 2022 the projects created will automatically find sqlite3.dll and sqlite3.lib.
SQLite import and export CSV
It is possible to import and export between comma separated texts and tables. This can be done with the command shell or with the GUI SQLiteStudio program (see Import a CSV File Into an SQLite Table (sqlitetutorial.net) and Export SQLite Database To a CSV File (sqlitetutorial.net)).
SQLite resources
SQLite Resources (sqlitetutorial.net)
SQLite Tutorial - An Easy Way to Master
SQLite Fast SQLite Home Page
SQLite Tutorial - w3resource
SQLite Exercises, Practice, Solution - w3resource
fnc12/sqlite_orm: ❤SQLite ORM light header only library for modern C++ (github.com)
Debugging tips
Sync_schema return value
For information as to what storage.sync_schema() has done we can capture its return type which is a std::map like so:
auto m = storage.sync_schema24(true);
std::ostringstream oss;
for (auto& n : m) {
oss << n.first << " " << n.second << "\t";
}
auto s = oss.str();
Access to Generated SQL
For any statement you can obtain the generated SQL with the following steps:
First let’s see a SELECT:
auto expression = select(columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission,
&Employee::m_job),
order_by(case_<double>()
.when(is_equal(&Employee::m_job, "SalesMan"),
then(&Employee::m_commission))
.else_(&Employee::m_salary).end()).desc());
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
auto rows = storage.execute(statement);
Now let’s see an INSERT:
auto expression = insert(into<Employee>(),
columns(&Employee::m_ename, &Employee::m_salary, &Employee::m_commission, &Employee::m_job),
values(std::make_tuple("Juan", 224000, 200, "Eng")));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
Now an UPDATE:
auto expression = update_all(set(c(&Employee::m_salary) = c(&Employee::m_salary) * 1.3),
where(c(&Employee::m_job) == "Clerk"));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
Finally a DELETE:
auto expression = remove_all<Employee>(where(c(&Employee::m_empno) == 6));
std::string sql = storage.dump(expression);
auto statement = storage.prepare(expression);
storage.execute(statement);
For the object version of these calls, we cannot access so readily the corresponding SQL but it is very predictable:
For object SELECT:
auto objects = storage.get_all<Employee>(); // SELECT * FROM EMP
auto employee = storage.get<Employee>(7499); // SELECT * FROM EMP WHERE id = 7499
For object INSERT:
// INSERT INTO EMP ( 'ALL COLUMNS EXCEPT PRIMARY KEY COLUMNS' )
// VALUES ( 'VALUES TAKEN FROM emp OBJECT')
Employee emp{ -1, "JOSE", "ENG", std::nullopt, "17-DEC-1980", 32000, std::nullopt, 10 };
emp.m_empno = storage.insert(emp);
For object UPDATE:
// UPDATE Emp
// SET
// column_name = emp.field_name // for all columns except primary key columns
// // ....
// WHERE empno = emp.m_empno;
emp.m_salary *= 1.3;
storage.update(emp);
For object DELETE:
// DELETE FROM Emp WHERE empno = emp.m_empno
storage.remove<Employee>(emp.m_empno);
// DELETE FROM Emp WHERE 'where clause'
storage.remove_all<Employee>(where(c(&Employee::m_salary) < 1000));
// DELETE FROM Emp
storage.remove_all<Employee>();
The Future of sqlite_orm
The most important features missing from sqlite_orm currently are support for views and common table expressions, in particular as represented by the WITH clause (see The WITH Clause (sqlite.org)) and The Simplest SQLite Common Table Expression Tutorial « Expensify Blog. An example of a dynamic from (which exemplify common table expressions) follows:
select depno, sum(salary) as total_sal, sum(bonus) as total_bonus from
(
select e.empno,
e.ename,
e.salary,
e.deptno,
b.type,
e.salary * case
when b,type = 1 then .1
when b.type = 2 then .2
else .3
end as bonus
from emp e, emp_bonus b
where e.empno = b.empno
and e.deptno =20
) y
group by deptno
and an example of a WITH clause follows:
WITH RECURSIVE approvers(x) AS (
SELECT 'Joanie'
UNION ALL
SELECT company.approver
FROM company, approvers
WHERE company.name=approvers.x AND company.approver IS NOT NULL
)
SELECT * FROM approvers;
References
[CPPTMP,2005] David Abrahams, Aleksey Gurtovoy. C++ Template Metaprogramming. Addison Wesley, 2005
Author Contact Information
The author of this guide Juan Dent-Herrera can be contacted at juandent@mac.com or by phone at (506) 8718-1237. Feel free to contact me. I am more than willing to help you with any concern or doubt you may have!


评论区